Jak znormalizować tablicę liczb dodatnich i ujemnych, aby zawierały się w przedziale od 0 do 1?
Używanie Brain do dostarczania tablicy danych z liczbami dodatnimi i ujemnymi; tablica wyjściowa będzie miała wartości 0 i 1 i uważam, że Brain dopuszcza tylko dane wejściowe od 0 do 1. Jak więc znormalizować tablicę liczb ujemnych i dodatnich, aby spełniała te wymagania?
Nazywa się to normalizacją opartą na jedności. Jeśli masz wektor X, możesz uzyskać jego znormalizowaną wersję, powiedzmy Z, wykonując:
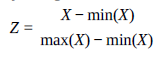
Znajdź największą liczbę dodatnią i najmniejszą (najbardziej ujemną) liczbę w tablicy. Dodaj wartość bezwzględną najmniejszej (najbardziej ujemnej) liczby do każdej wartości w tablicy. Podzielić każdy wynik przez różnicę między największą i najmniejszą liczbą.
Korzystam z Google Analytics w mojej aplikacji mobilnej, aby zobaczyć, jak różni użytkownicy korzystają z aplikacji. Rysuję ścieżkę na podstawie stron, na które przechodzą. Biorąc pod uwagę listę ścieżek dla, powiedzmy, 100 użytkowników, jak mam zająć się grupowaniem użytkowników. Którego algorytmu użyć? Swoją drogą, myślę o wykorzystaniu pakietu sckit Learn do implementacji. Mój zbiór danych (w csv) wyglądałby tak:
DeviceID, Pageid, Time_spent_on_Page, Transition. <br>
ABC, Strona1, 3s, 1-> 2. <br>
ABC, Strona2, 2s, 2-> 4. <br>
ABC, Strona 4,1s, 4-> 1. <br>
A więc ścieżka to 1-> 2-> 4-> 1, gdzie 1,2,4 to Pageids.
Istnieją 2 różne podejścia do Twojego problemu:
Podejście wykresowe
* Jak stwierdzono, masz ważony ukierunkowany wykres i chcesz pogrupować ścieżki. Wspominam jeszcze raz, ponieważ ważne jest, aby wiedzieć, że twój problem nie jest problemem związanym z klastrowaniem wykresów lub wykrywaniem społeczności, w którym wierzchołki są skupione!
* Tworząc wykres w networkx przy użyciu dwóch ostatnich kolumn danych, możesz dodać czas spędzony jako wagę i użytkowników, którzy przekazali ten link jako atrybut krawędzi. W końcu będziesz mieć różne funkcje do grupowania: zbiór wszystkich wierzchołków, które dana osoba kiedykolwiek spotkała na wykresie, całkowity, średni i standardowy czas spędzony, parametry rozkładu najkrótszej ścieżki… które można wykorzystać do grupowania zachowań użytkowników.
Dane standardowe
* Wszystko powyższe można zrobić, efektywnie odczytując dane w macierzy. Jeśli weźmiesz pod uwagę każdą krawędź dla określonego użytkownika jako pojedynczy wiersz (tj. Będziesz mieć MxN wierszy, gdzie M to liczba użytkowników, a N to liczba krawędzi na wypadek, gdybyś trzymał się 100 przypadków!) I dodasz właściwości jako kolumny, Prawdopodobnie będę w stanie skupić zachowania. jeśli użytkownik przekroczył krawędź n razy, w wierszu odpowiadającym temu użytkownikowi i tej krawędzi dodaj kolumnę zliczającą o wartości n i taką samą dla czasu spędzonego itp. Krawędzie początkowe i końcowe są również pouczające. Uważaj, aby nazwy węzłów były zmiennymi kategorialnymi.
Jeśli chodzi o algorytmy klastrowania, możesz znaleźć wystarczająco dużo, jeśli spojrzysz na SKlearn. Mam nadzieję, że to pomogło.
Jak nauczyć się wykrywania spamu?
Chcę się dowiedzieć, jak działa wykrywacz spamu. Nie próbuję budować produktu komercyjnego, będzie to dla mnie poważna nauka. Dlatego szukam zasobów, takich jak istniejące projekty, kod źródłowy, artykuły, artykuły itp., Które mogę śledzić. Chcę uczyć się na przykładach, nie sądzę, że jestem wystarczająco dobry, aby robić to od zera. Idealnie, chciałbym ubrudzić sobie rękę w języku bayesowskim. Czy jest coś takiego? Język programowania nie jest dla mnie problemem.
ALE ponieważ chcesz rozpocząć prosty projekt edukacyjny, radzę nie przeglądać prac (które oczywiście nie są podstawowe), ale spróbować zbudować własnego bayesowskiego ucznia, co nie jest takie trudne. Osobiście sugeruję slajdy z wykładów Andrew Moore’a na temat probabilistycznych modeli graficznych, które są dostępne bezpłatnie i można się z nich uczyć w prosty i krok po kroku. Jeśli potrzebujesz bardziej szczegółowej pomocy, po prostu skomentuj tę odpowiedź, a chętnie pomogę.
W kursie uczenia maszynowego Andrew Ng na Coursera (w pewnym sensie kursie flagowym dla Coursera) ćwiczenie programistów dla Support Vector Machines było przykładem klasyfikatora spamu. Wykłady są świetne, wręcz znane i warte obejrzenia.
Podstawowe wprowadzenie do metody bayesowskiej wykrywania spamu znajduje się w książce „Doing Data Science – Straight Talk from the Frontline” autorstwa Cathy O’Neil, Rachel Schutt. Ten rozdział jest dobry, ponieważ wyjaśnia, dlaczego inne popularne modele nauki o danych nie
pracują dla klasyfikatorów spamu. Cała książka używa R w całym tekście, więc podnieś ją tylko, jeśli jesteś zainteresowany pracą z R. Używa ona adresu e-mail firmy Enron jako danych szkoleniowych, ponieważ ma już wiadomości e-mail podzielone na spam / nie spam.
Wdrażanie komplementarnego Bayesa naiwnego w Pythonie?
Problem
Próbowałem użyć Naive Bayes na oznaczonym zestawie danych dotyczących przestępstw, ale uzyskałem naprawdę słabe wyniki (7% dokładność). Naiwny Bayes działa znacznie szybciej niż inne alogorytmy, których używałem, więc chciałem spróbować dowiedzieć się, dlaczego wynik był tak niski.
Badania
Po przeczytaniu stwierdziłem, że Bayes Naive powinien być używany ze zbalansowanymi zestawami danych, ponieważ ma odchylenie dla klas o wyższej częstotliwości. Ponieważ moje dane są niezrównoważone, chciałem spróbować użyć Complementary Naive Bayes, ponieważ jest on przeznaczony specjalnie do radzenia sobie z wypaczeniami danych. W artykule opisującym proces aplikacja służy do klasyfikacji tekstu, ale nie rozumiem, dlaczego ta technika nie zadziałaby w innych sytuacjach. Możesz znaleźć artykuł, do którego się odwołuję tutaj. Krótko mówiąc, chodzi o to, aby używać wag na podstawie przypadków, w których klasa się nie pojawia. Po przeprowadzeniu pewnych badań udało mi się znaleźć implementację w Javie, ale niestety nie znam żadnej Javy i po prostu nie rozumiem algorytmu wystarczająco dobrze, aby zaimplementować siebie.
Gdzie mogę znaleźć implementację w Pythonie? Jeśli tego nie ma, jak mam go zaimplementować?
Naiwny Bayes powinien być w stanie obsłużyć niezrównoważone zbiory danych. Przypomnij sobie, że formuła Bayesa to
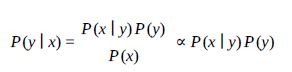
Zatem P (x | y) P (y) bierze pod uwagę poprzednik.
W Twoim przypadku może przesadzasz i potrzebujesz wygładzenia? Możesz zacząć od wygładzenia +1 i sprawdzić, czy daje jakieś ulepszenia. W Pythonie, używając numpy, zaimplementowałbym wygładzanie w ten sposób:
table = # counts for each feature
PT = (table + 1) / (table + 1).sum(axis=1, keepdims=1)
Zwróć uwagę, że to daje Ci Wielomianowy Naive Bayes – który ma zastosowanie tylko do danych jakościowych. Mogę również zasugerować następujący link: http://www.itshared.org/2015/03/naive-bayes-onapache-flink.html. Chodzi o wdrożenie Naive Bayes w Apache Flink. Chociaż jest to Java, może da ci trochę teorii potrzebnej do lepszego zrozumienia algorytmu.
Jak znaleźć podobieństwo między różnymi czynnikami w zbiorze danych
Załóżmy, że mam zbiór danych z różnymi obserwacjami różnych osób i chcę pogrupować osoby, aby dowiedzieć się, która osoba jest najbliższa drugiej. Chcę również mieć miarę, aby wiedzieć, jak blisko siebie są i poznać znaczenie statystyczne.
Dane
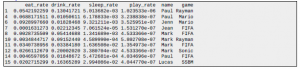
Odtwórz to:
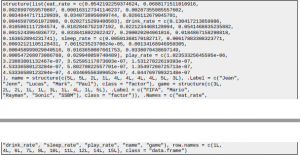
Pytanie
Biorąc pod uwagę zbiór danych jako inny (z cechą ciągłą i kategorialną), skąd mogę wiedzieć, czy osoba (odpowiedź kategoryczna) zidentyfikowana za pomocą nazwiska jest bardziej skorelowana z inną osobą?
Jednym ze sposobów jest znormalizowanie wartości ilościowych (gra, jedzenie, picie, wskaźniki snu), aby wszystkie miały ten sam zakres (powiedzmy 0 -> 1), a następnie przypisanie każdej grze do jej własnego „wymiaru”, który przyjmuje wartość 0 lub 1. Przekształć każdy wiersz w wektor i znormalizuj długość do 1. Teraz możesz porównać iloczyn skalarny wektorów znormalizowanych dowolnych dwóch osób jako miarę podobieństwa. Coś takiego jest często używane w eksploracji tekstu
Kod R dla macierzy podobieństwa Zakłada, że zapisałeś ramkę danych w zmiennej „D”
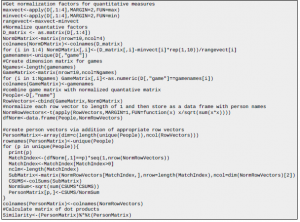
Pomimo znormalizowanej odległości euklidesowej można również przyjrzeć się odległości Pearsona jako miary podobieństwa.
Jak uniknąć overfittingu w losowym lesie?
- Chcę uniknąć overfittingu w przypadkowym lesie. W związku z tym zamierzam użyć mtry, nodesize i maxnodes itp. Czy mógłbyś mi pomóc, jak wybrać wartości dla tych parametrów. Używam R.
- Również, jeśli to możliwe, powiedz mi, jak mogę użyć walidacji krzyżowej k-krotnej dla losowego lasu. w R.
W porównaniu z innymi modelami, Random Forests są mniej skłonne do nadmiernego dopasowania, ale nadal jest to coś, czego chcesz wyraźnie unikać. Dostrajanie parametrów modelu jest zdecydowanie jednym z elementów unikania nadmiernego dopasowania, ale nie jedynym. W rzeczywistości powiedziałbym, że twoje funkcje treningowe z większym prawdopodobieństwem doprowadzą do nadmiernego dopasowania niż parametry modelu, szczególnie w przypadku losowych lasów. Myślę więc, że kluczem do sukcesu jest posiadanie niezawodnej metody oceny modelu pod kątem sprawdzania nadmiernego dopasowania bardziej niż cokolwiek innego, co prowadzi nas do drugiego pytania. Jak wspomniano powyżej, przeprowadzenie walidacji krzyżowej pozwoli uniknąć nadmiernego dopasowania. Wybór najlepszego modelu na podstawie wyników CV doprowadzi do modelu, który nie jest nadmiernie dopasowany, co niekoniecznie musi mieć miejsce w przypadku błędu „po wyjęciu z torby”. Najłatwiejszym sposobem uruchomienia CV w R jest użycie pakietu karetki. Poniżej prosty przykład:
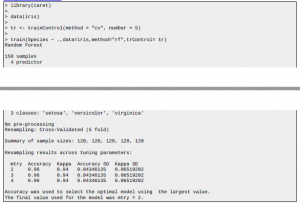
@xof6 ma rację w tym sensie, że im większa głębia ma model, tym bardziej ma tendencję do nadmiernego dopasowania, ale chciałem dodać więcej parametrów, które mogą być dla ciebie przydatne. Nie wiem, którego pakietu używasz z R i R w ogóle nie znam, ale myślę, że muszą być tam zaimplementowane odpowiedniki tych parametrów. Liczba drzew – im większa liczba, tym mniejsze prawdopodobieństwo, że las będzie się nadmiernie dopasowywać. Oznacza to, że ponieważ każde drzewo decyzyjne uczy się jakiegoś aspektu danych szkoleniowych, masz więcej opcji do wyboru, że tak powiem. Liczba cech – ta liczba określa, ile cech uczy się każde drzewo. Wraz ze wzrostem tej liczby drzewa stają się coraz bardziej skomplikowane, dlatego uczą się wzorców, których nie ma w danych testowych. Znalezienie odpowiedniej wartości zajmie trochę czasu, ale takie jest właśnie uczenie maszynowe. Poeksperymentuj również z ogólną głębią, jak wspomnieliśmy!
P: R – Interpretacja wykresu sieci neuronowych
Wiem, że są podobne pytania dotyczące statystyk SE, ale nie znalazłem takiego, które spełniałoby moją prośbę; proszę, zanim oznaczysz pytanie jako duplikat, pinguj mnie w komentarzu. Prowadzę sieć neuronową w oparciu o Neuralnet do prognozowania szeregów czasowych indeksu SP500 i chcę zrozumieć, jak mogę zinterpretować poniższy wykres:
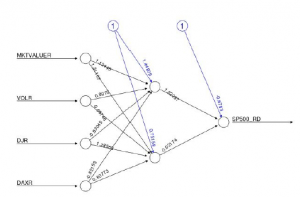
W szczególności chciałbym zrozumieć, jaka jest interpretacja wagi warstwy ukrytej i wagi wejściowej; czy ktoś mógłby mi wyjaśnić, jak interpretować ten numer, proszę? Każda wskazówka zostanie doceniona.
Jak stwierdza David w komentarzach, jeśli chcesz zinterpretować model, prawdopodobnie będziesz chciał zbadać coś innego niż sieci neuronowe. To powiedziawszy, chcesz intuicyjnie zrozumieć wykres sieci, najlepiej pomyśleć o tym w odniesieniu do obrazów (coś, w czym sieci neuronowe są bardzo dobre).
- Węzły najbardziej po lewej stronie (tj. Węzły wejściowe) to surowe zmienne danych.
- Czarne strzałki (i związane z nimi liczby) to wagi, o których możesz pomyśleć jako o tym, ile ta zmienna wpływa na następny węzeł. Niebieskie linie to wagi odchylenia. Cel tych odważników można znaleźć w doskonałej odpowiedzi tutaj.
- Węzły środkowe (tj. Wszystko pomiędzy węzłami wejściowymi i wyjściowymi) to węzły ukryte. W tym pomaga analogia obrazu. Każdy z tych węzłów stanowi komponent, który sieć uczy się rozpoznawać. Na przykład nos, usta lub oko. Nie jest to łatwe do określenia i jest znacznie bardziej abstrakcyjne, gdy mamy do czynienia z danymi nie będącymi obrazami.
- Węzeł skrajnie prawy (węzły wyjściowe) jest końcowym wyjściem twojej sieci neuronowej. Zauważ, że to wszystko pomija funkcję aktywacji, która byłaby zastosowana również na każdej warstwie sieci.
Jakie funkcje z fal dźwiękowych można wykorzystać dla kompozytora utworów AI?
Planuję stworzyć kompozytora utworów AI, który zbierałby kilka piosenek z jednego instrumentu, wydobywał nuty (takie jak ABCDEFG) i pewne cechy z fali dźwiękowej, przeprowadzał uczenie maszynowe (najprawdopodobniej poprzez powtarzające się sieci neuronowe) i wyjście sekwencja nut ABCDEFG (czyli generowanie własnych piosenek / muzyki). Myślę, że byłby to problem z uczeniem się bez nadzoru, ale nie jestem pewien. Pomyślałem, że użyję powtarzających się sieci neuronowych, ale mam kilka pytań, jak podejść do tego:
– Jakie cechy powinienem wydobyć z fali dźwiękowej, aby muzyka wyjściowa była melodyjna?
– Czy w przypadku powtarzających się sieci neuronowych możliwe jest wygenerowanie wektora sekwencyjnych nut muzycznych (ABCDEF)?
– Czy jest jakiś sprytny sposób, w jaki mogę wykorzystać cechy fal dźwiękowych, a także sekwencję nut?
Po pierwsze, zignoruj hejterów. Zacząłem pracować nad ML in Music dawno temu i uzyskałem kilka stopni naukowych, korzystając z tej pracy. Kiedy zaczynałem, zadawałem ludziom takie same pytania, jak ty. To fascynująca dziedzina i zawsze znajdzie się miejsce dla kogoś nowego. My wszyscy muszą gdzieś zacząć. Dziedziny nauki, o które pytasz, to wyszukiwanie informacji o muzyce (łącze do Wiki) i muzyka komputerowa (łącze do wiki). Dokonałeś dobrego wyboru zawężając swój
problem z pojedynczym instrumentem (muzyka monofoniczna), ponieważ muzyka polifoniczna znacznie zwiększa trudność. Naprawdę próbujesz rozwiązać dwa problemy:
1) Automatyczna transkrypcja muzyki monofonicznej (więcej lektur), która jest problemem wyodrębniania nut z pojedynczego utworu muzycznego instrumentu.
2) Kompozycja algorytmiczna (więcej lektur) czyli problem generowania nowej muzyki z wykorzystaniem korpusu transkrybowanej muzyki.
Odpowiadając bezpośrednio na pytania: myślę, że byłby to problem z uczeniem się bez nadzoru, ale nie jestem pewien. Ponieważ są tutaj dwa problemy z nauką, istnieją dwie odpowiedzi. W przypadku automatycznej transkrypcji prawdopodobnie będziesz chciał zastosować metodę uczenia nadzorowanego, w której klasyfikacja to notatki, które próbujesz wyodrębnić. W przypadku problemu kompozycji algorytmicznej może to faktycznie przebiegać w obie strony. Niektóre odczyty w obu obszarach będą jasne, to dużo. Jakie cechy powinienem wydobyć z fali dźwiękowej, aby muzyka wyjściowa była melodyjna? W MIR jest wiele funkcji powszechnie używanych. @abhnj wymienił MFCC w swojej odpowiedzi, ale jest ich o wiele więcej. Analiza cech w MIR odbywa się w kilku domenach, a każda z nich ma cechy. Niektóre domeny to:
- Domena częstotliwości (są to wartości, które słyszymy przez głośnik)
- Dziedzina widmowa (ta dziedzina jest obliczana za pomocą funkcji Fouriera (Przeczytaj o szybkiej transformacji Fouriera) i może być przekształcana przy użyciu kilku funkcji (wielkość, moc, wielkość logarytmiczna, moc logarytmiczna)
- Domena pików (domena amplitud i pików widmowych w domenie widmowej)
- Dziedzina harmonicznych
Jednym z pierwszych problemów, jakie napotkasz, jest segmentacja lub „wycinanie” sygnału muzycznego, aby można było wyodrębnić cechy. To jest problem segmentacji (niektórych odczytów), który sam w sobie jest złożony. Po przycięciu źródła dźwięku możesz zastosować różne funkcje do segmentów przed wyodrębnieniem z nich funkcji. Niektóre z tych funkcji (zwane funkcjami okna) to: Rectangular, Hamming, Hann, Bartlett, Triangular, Bartlett_hann, Blackman i Blackman_harris. Po wycięciu segmentów z domeny możesz wyodrębnić funkcje reprezentujące te segmenty. Niektóre z nich będą zależeć od wybranej domeny. Kilka przykładów funkcji to: Twoje normalne cechy statystyczne (średnia, wariancja, skośność itp.), ZCR, RMS, centrum widmowe, nieregularność widmowa, płaskość widmowa, tonalność widmowa, grzebień widmowy, nachylenie widmowe, spadek widmowy, głośność widmowa, Widmo widmowe,
Współczynnik harmonicznych nieparzystych parzystych, MFCC i skala kory. Jest ich o wiele więcej, ale to są dobre podstawy. Czy w przypadku powtarzających się sieci neuronowych możliwe jest wyprowadzenie wektora sekwencyjnych nut muzycznych (ABCDEF)? Tak to jest. Było już kilka prac, aby to zrobić. (Oto kilka odczytów) Czy mogę w jakiś sprytny sposób wykorzystać cechy fal dźwiękowych, a także sekwencję nut? Standardową metodą jest użycie powyższego wyjaśnienia (domena, segment, ekstrakt funkcji) itp. Aby zaoszczędzić sobie trochę pracy, bardzo polecam zacząć od frameworka MIR, takiego jak MARSYAS (Marsyas). Zapewnią Ci wszystkie podstawy ekstrakcji cech. Istnieje wiele frameworków, więc po prostu znajdź taki, który używa języka, w którym czujesz się komfortowo.
Uważam, że chodzi o to, że chcesz uczyć się z utworów muzycznych i spróbować wygenerować melodię z wyszkolonej instancji. Zobaczmy, czy uda mi się ustawić prosty model, aby to zrobić, a następnie możesz dokonać ekstrapolacji z tego miejsca. Tak więc MFCC jest dobrą funkcją podczas pracy z dźwiękiem. Możesz użyć tego do wyodrębnienia funkcji z, powiedzmy, 1-2 sekundowych okien utworu. Masz teraz odcisk palca dla pliku audio. Spójrz na warunkowo ograniczone maszyny Boltzmanna. Są to sieci neuronowe, które używają wielu stanów binarnych do kodowania informacji o szeregach czasowych. Jak widać na stronie internetowej, trenowali oni na danych dotyczących ludzkiego chodu i mogą teraz generować własny ludzki chód. Zasadniczo tego chcesz, ale nie w przypadku plików muzycznych. Możesz więc trenować CRBM na wektorach Audio MFCC, które posiadasz. Po zakończeniu treningu, aby wygenerować plik audio, możesz „zapełnić” CRBM kilkusekundową melodią lub po prostu losowo go zainicjować. Następnie pozwól CRBM oszaleć i zarejestruj wszystko, co wyprodukuje. To jest twój nowy plik audio. Aby wyprodukować kolejną próbkę, użyj innego ziarna. To rozwiązuje pytanie, jak można zaimplementować schemat generowania „melodii”. Oczywiście istnieją różne odmiany. Oprócz MFCC możesz dodać do siebie inne funkcje. Możesz także użyć innych predyktorów szeregów czasowych, takich jak modele LSTM lub Markov. Biorąc to wszystko pod uwagę, problem generowania muzyki może być znacznie bardziej zniuansowany, niż się wydaje na pierwszy rzut oka. Algorytmy uczenia maszynowego po prostu stosują wcześniej wyuczone wzorce w danych. Jak to się ma do „tworzenia” nowej muzyki, to kwestia filozoficzna. Jeśli przeanalizujemy wspomniany wyżej algorytm, zasadniczo CRBM wygeneruje następny wynik w oparciu o poznany rozkład prawdopodobieństwa. Byłoby bardzo interesujące zobaczyć, jaki rodzaj produkcji generuje, gdy wspomniana dystrybucja to nuty.
Wyprowadzanie ufności z rozkładu prawdopodobieństw klas dla prognozy
Od czasu do czasu napotykam ten problem i zawsze uważałem, że powinno być oczywiste rozwiązanie. Mam prawdopodobieństwa dla potencjalnych klas (z jakiegoś klasyfikatora). Zaproponuję prognozę klasy z najwyższym prawdopodobieństwem, jednak chciałbym również dołączyć zaufanie do tej prognozy. Przykład: Jeśli mam klasy [C1, C2, C3, C4, C5] i moje prawdopodobieństwa to {C1: 50, C2: 12, C3: 13, C4: 12, C5: 13}, moja pewność co do przewidywania C1 powinna być wyższa niż gdybym miał prawdopodobieństwa {C1: 50, C2: 45, C3: 2, C4: 1, C5: 2}. Zgłaszanie, że przewiduję klasę C1 z 60% prawdopodobieństwem, to nie wszystko. powinienem być w stanie uzyskać pewność z rozkładu prawdopodobieństw. Jestem pewien, że istnieje znana metoda rozwiązania tego problemu, ale nie wiem, co to jest.
Doprowadzenie tego do skrajności dla wyjaśnienia: gdybym miał klasę C1 ze 100% prawdopodobieństwem (i zakładając, że klasyfikator miał dokładną reprezentację każdej klasy), to byłbym bardzo pewien, że C1 jest poprawną klasyfikacją. Z drugiej strony, gdyby wszystkie 5 klas miało prawie równe prawdopodobieństwo (powiedzmy, że wszystkie mają około 20%), to byłbym bardzo niepewny, twierdząc, że jakakolwiek klasyfikacja jest poprawna. Te dwa skrajne przypadki są bardziej oczywiste, wyzwaniem jest zdobycie zaufania do przykładów pośrednich jak ten powyżej. Wszelkie sugestie lub odniesienia byłyby bardzo pomocne. Z góry dziękuję.
Jeśli mam Klasy [C1, C2, C3, C4, C5], a moje prawdopodobieństwa to {C1: 50, C2: 12, C3: 13, C4: 12, C5: 13}, moja pewność w przewidywaniu C1 powinna być wyższa niż gdyby Miałem prawdopodobieństwa {C1: 50, C2: 45, C3: 2, C4: 1, C5: 2}.
Zakładając, że te prawdopodobieństwa są dokładne, nie jest to prawdą. W drugim przypadku możesz być dużo bardziej przekonany, że podstawowa prawda jest równa C1 lub C2, ale w kategoriach absolutnej pewności co do C1 prawdopodobieństwo jest takie samo w obu przykładach. Aby to zilustrować na bardziej przejrzystym przykładzie, gdybyś miał 100-stronną kostkę, która miała 50 boków oznaczonych „C1”, wówczas etykiety na pozostałych 50 stronach nie mają znaczenia dla prawdopodobieństwa, że wyrzucisz „C1”. Mając to na uwadze, twoje prawdopodobieństwa z twojego modelu z pewnością nie są doskonałe, więc może istnieć sposób na wykorzystanie korelacji wewnątrzklasowych, aby je poprawić. Czy możesz podać więcej szczegółów na temat swojego konkretnego problemu i procesu modelowania, którego użyłeś do obliczenia prawdopodobieństwa?