Baza danych to zorganizowany zbiór danych. Dane są zazwyczaj organizowane w celu modelowania odpowiednich aspektów rzeczywistości (na przykład dostępności pokoi w hotelach), w sposób, który obsługuje procesy wymagające tych informacji (na przykład znalezienie hotelu z wolnymi miejscami). Duża część stron internetowych i aplikacji opiera się na bazach danych. Są kluczowym składnikiem systemów telekomunikacyjnych, systemów bankowych, gier wideo i niemal każdego innego oprogramowania lub urządzenia elektronicznego, które przechowuje pewną ilość trwałych informacji. Oprócz trwałości systemy baz danych zapewniają szereg innych właściwości, które czynią je wyjątkowo przydatnymi i wygodnymi: niezawodność, wydajność, skalowalność, kontrola współbieżności, abstrakcja danych i języki zapytań wysokiego poziomu. Bazy danych są tak wszechobecne i ważne, że absolwenci informatyki często podają swoją klasę baz danych jako najbardziej przydatną w swojej branży lub karierze absolwenta. Termin „baza danych” nie powinien być mylony z systemem zarządzania bazami danych (DBMS). DBMS to oprogramowanie systemowe używane do tworzenia baz danych i zarządzania nimi oraz zapewniania użytkownikom i aplikacjom dostępu do baz danych. Baza danych jest do DBMS jak dokument do edytora tekstu.
PYTANIA: Czy to porównanie Neo4j z czasem wykonania RDBMS jest prawidłowe?
Relacje na wykresie w naturalny sposób tworzą ścieżki. Zapytanie lub przejście przez wykres obejmuje określone ścieżki. Ze względu na zasadniczo zorientowany na ścieżkę charakter modelu danych, większość operacji opartych na ścieżkach graficznych baz danych jest ściśle dopasowana do sposobu, w jaki dane są ułożone, co czyni je niezwykle wydajnymi. W swojej książce Neo4j in Action, Partner i Vukotic przeprowadzają eksperyment przy użyciu sklepu relacyjnego i Neo4j. Porównanie pokazuje, że baza danych grafów jest znacznie szybsza dla połączonych danych niż sklep relacyjny. Eksperyment Partnera i Vukotic ma na celu znalezienie przyjaciół-przyjaciół w sieci społecznościowej do maksymalnej głębokości pięciu. Biorąc pod uwagę dowolne dwie osoby wybrane losowo, czy istnieje ścieżka, która ich łączy, co najwyżej pięć związków? W przypadku sieci społecznościowej zawierającej 1 000 000 osób, z których każda ma około 50 znajomych, wyniki zdecydowanie sugerują, że bazy danych wykresów są najlepszym wyborem dla połączonych danych, jak widać poniżej
![]()
Na głębokości dwa (znajomi znajomych) zarówno relacyjna baza danych, jak i baza danych grafów działają wystarczająco dobrze, abyśmy mogli rozważyć użycie ich w systemie online. Podczas gdy zapytanie Neo4j działa w dwóch trzecich czasu relacyjnego, użytkownik końcowy ledwo zauważyłby różnicę w milisekundach między nimi. Zanim jednak osiągniemy głębokość trzecią (przyjaciel-przyjaciel-przyjaciel), jasne jest, że relacyjna baza danych nie jest w stanie poradzić sobie z zapytaniem w rozsądnych ramach czasowych: trzydzieści sekund potrzebnych do wypełnienia byłoby całkowicie niedopuszczalne dla systemu online. Natomiast czas odpowiedzi Neo4j pozostaje stosunkowo płaski: zaledwie ułamek sekundy, aby wykonać zapytanie – zdecydowanie wystarczająco szybko dla systemu online. Na głębokości czwartej relacyjna baza danych wykazuje paraliżujące opóźnienie, co czyni ją praktycznie bezużyteczną dla systemu online. Czasy Neo4j również nieco się pogorszyły, ale opóźnienie jest na obrzeżach akceptacji dla responsywnego systemu online. Wreszcie na głębokości piątej relacyjna baza danych po prostu trwa zbyt długo, aby ukończyć zapytanie. Natomiast Neo4j zwraca wynik po około dwóch sekundach. Na głębokości piątej okazuje się, że prawie cała sieć jest naszym przyjacielem: w wielu rzeczywistych przypadkach użycia prawdopodobnie skrócilibyśmy wyniki i czasy.
Pytania są następujące:
* Czy to rozsądny test do naśladowania tego, co można znaleźć poza siecią społecznościową? (To znaczy, że prawdziwe sieci społecznościowe zwykle mają na przykład węzły z około 50 przyjaciółmi; wydaje się, że model „wzbogacania się bogatszego” byłby bardziej naturalny dla sieci społecznościowych, choć może się mylić).
* Czy bez względu na naturalność emulacji istnieje powód, by sądzić, że wyniki są wyłączone lub nie można ich odtworzyć?
Patrząc na dokument zatytułowany Anatomia Facebooka, zauważam, że mediana wynosi 100. Patrząc na wykres funkcji skumulowanej, mogę się założyć, że średnia jest wyższa, blisko 200. Więc 50 nie wydaje się tutaj najlepszą liczbą. Myślę jednak, że nie jest to tutaj główny problem.
Głównym problemem jest brak informacji o sposobie korzystania z bazy danych. Wydaje się uzasadnione, że pamięć danych zaprojektowana specjalnie dla struktur grafowych jest bardziej wydajna niż tradycyjne RDBM. Jednak nawet jeśli RDBM nie są zgodne z najnowszymi trendami w zakresie przechowywania danych z wyboru, systemy te ewoluowały w sposób ciągły w wyścigu z wymiarami zestawu danych. Istnieją różne rodzaje możliwych projektów, różne sposoby indeksowania danych, ulepszenia związane z współbieżnością i tak dalej. Podsumowując, uważam, że jeśli chodzi o odtwarzalność, w badaniu brakuje właściwego opisu sposobu zaprojektowania schematu bazy danych. Nie oczekuję, że baza danych zdominuje takiego króla przesłuchań, ale spodziewam się, że przy dobrze dostrojonym projekcie różnice nie będą tak ogromne.
Istnieją dobre / szybkie sposoby modelowania wykresów w RDBMS oraz głupie / wolne sposoby.
* Niektórzy używają sprytnego indeksowania i przechowywanych procesów, handlowania obciążeniem procesora i dostrajanych tabel temp na dyskach RAM dla szybszej prędkości pobierania wykresów.
* Niektórzy używają wstępnie obliczonych ścieżek graficznych (może to być mniej wykonalne w scenariuszu z sieciami społecznościowymi, ale w drzewie z większością węzłów stanowiących węzły liści, jest to całkiem niezły kompromis w stosunku do czasu
* Niektóre z nich po prostu obliczają w pętli, używając niestrunionej tabeli indeksowanej. Z #s wyrzuconych w artykule, który pachnie jak to zrobili (30 sekund – wydajność na dość niewielkim zestawie danych)
Czy to dobry przypadek dla NOSQL?
Obecnie pracuję przed projektem, który mógłbym rozwiązać za pomocą relacyjnej bazy danych w stosunkowo bolesny sposób. Słysząc tyle o NOSQL, zastanawiam się, czy nie ma bardziej odpowiedniego sposobu rozwiązania tego problemu:
Załóżmy, że śledzimy grupę zwierząt w lesie (n ~ 500) i chcielibyśmy prowadzić rejestr obserwacji (jest to fikcyjny scenariusz). Chcielibyśmy przechowywać następujące informacje w bazie danych:
* unikalny identyfikator dla każdego zwierzęcia
* opis zwierzęcia o uporządkowanych polach: gatunek, rodzaj, rodzina,…
* wolne pole tekstowe z dodatkowymi informacjami
* każdy punkt czasowy, w którym został wykryty w pobliżu punktu odniesienia
* zdjęcie zwierzęcia
* wskazanie, czy dwa dane zwierzęta są rodzeństwem
I:
* później mogą pojawiać się dodatkowe funkcje, gdy pojawi się więcej danych
Chcielibyśmy móc wykonywać następujące typy zapytań:
* zwróć wszystkie zauważone zwierzęta w danym przedziale czasu
* zwróć wszystkie zwierzęta z danego gatunku lub rodziny
* wykonaj wyszukiwanie tekstu w wolnym polu tekstowym
Który konkretny system baz danych poleciłbyś? Czy jest jakiś samouczek / przykłady, których mógłbym użyć jako punktu wyjścia?
Trzy tabele: zwierzę, obserwacja i rodzeństwo. Obserwacja ma kolumnę animal_id, która prowadzi do tabeli zwierząt, a tabela rodzeństwa zawiera kolumny animal_1_id i animal_2_id, które wskazują, że dwa zwierzęta są rodzeństwem dla każdego wiersza. Nawet przy 5000 zwierząt i 100000 obserwacji nie sądzę, że czas zapytania będzie stanowić problem dla czegoś takiego jak PostgreSQL dla najbardziej rozsądnych zapytań (oczywiście możesz tworzyć nieuzasadnione zapytania, ale możesz to zrobić w dowolnym systemie).
Nie rozumiem więc, jak to jest „względnie bolesne”. W stosunku do czego? Jedyną złożonością jest tabela z rodzeństwem. W NOSQL możesz przechowywać pełną listę rodzeństwa w rekordzie dla każdego zwierzęcia, ale kiedy dodajesz relację z rodzeństwem, musisz dodać ją do rejestrów zwierząt obu rodzeństwa. Zarysowane przeze mnie podejście do tabeli relacyjnej istnieje tylko raz, ale kosztem przetestowania obu kolumn w celu znalezienia rodzeństwa zwierzęcia. Użyłbym PostgreSQL, a to daje opcję korzystania z PostGIS, jeśli masz dane lokalizacji – jest to geoprzestrzenne rozszerzenie PostgreSQL, które pozwala ci wykonywać zapytania przestrzenne (punkt w wielokącie, punkty w pobliżu punktu itp.), Co może być ty. Naprawdę nie sądzę, że właściwości baz danych NOSQL stanowią dla ciebie problem – nie zmieniasz swojego schematu co dziesięć minut, prawdopodobnie dbasz o to, aby baza danych była zgodna z ACID i nie potrzebujesz czegoś w Internecie skala.
Co sprawia, że kolumny kolumnowe są odpowiednie do analizy danych?
Jakie są zalety kolumnowych magazynów danych, które czynią je bardziej odpowiednimi do analizy danych i analiz?
Baza danych zorientowana na kolumny (= magazyn danych kolumnowych) przechowuje dane z tabeli kolumna po kolumnie na dysku, natomiast zorientowana wierszowo baza danych przechowuje dane tabeli wiersz po rzędzie. Istnieją dwie główne zalety korzystania z bazy danych zorientowanej na kolumny w porównaniu z bazą danych zorientowaną na wiersze. Pierwsza zaleta dotyczy ilości danych, które należy odczytać na wypadek, gdybyśmy wykonali operację tylko na kilku funkcjach. Rozważ proste zapytanie:
![]()
Tradycyjny moduł wykonujący czytałby całą tabelę (tj. wszystkie funkcje):
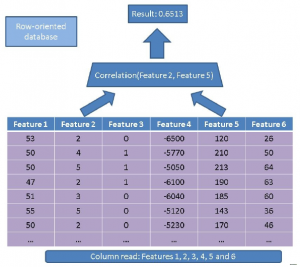
Zamiast tego, stosując nasze podejście oparte na kolumnach, musimy po prostu przeczytać kolumny, którymi jesteśmy zainteresowani:
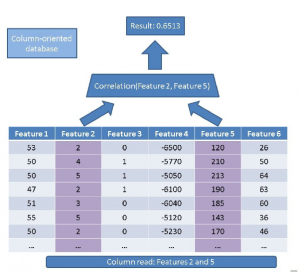
To zależy od tego, co robisz. Działanie z kolumnami ma dwie kluczowe zalety:
* całe kolumny można pominąć
* kompresja długości przebiegu działa lepiej na kolumnach (dla niektórych typów danych; w szczególności z kilkoma odrębnymi wartościami)
Ma jednak również wady:
* wiele algorytmów potrzebuje wszystkich kolumn i zapisuje tylko na raz (np. k-średnie) lub może nawet wymagać obliczenia macierzy odległości parami
* techniki kompresji działają dobrze tylko na rzadkich typach danych i czynnikach, ale niezbyt dobrze na ciągłych danych o podwójnej wartości
* dodatki w sklepach kolumnowych są drogie, więc nie jest idealne do przesyłania strumieniowego / zmiany danych
Przechowywanie kolumnowe jest bardzo popularne w przypadku OLAP, czyli „głupich analiz” (Michael Stonebraker) i oczywiście w przypadku przetwarzania wstępnego, w którym rzeczywiście możesz być zainteresowany odrzuceniem całych kolumn (ale najpierw musisz mieć uporządkowane dane – nie przechowujesz JSON w kolumnie format). Ponieważ układ kolumnowy jest naprawdę ładny np. licząc ile jabłek sprzedałeś w zeszłym tygodniu. W przypadku wielu zastosowań naukowych / do analizy danych właściwym rozwiązaniem są bazy tablicowe (plus oczywiście nieustrukturyzowane dane wejściowe). Na przykład. SciDB i RasDaMan.
W wielu przypadkach (np. głębokie uczenie się) macierze i tablice to typy danych, których potrzebujesz, a nie kolumny. Oczywiście MapReduce itp. Nadal może być przydatny w przetwarzaniu wstępnym. Może nawet dane kolumnowe (ale baza danych macierzy zwykle obsługuje również kompresję podobną do kolumn).
Nie korzystałem z kolumnowej bazy danych, ale użyłem formatu kolumnowego o otwartym kodzie źródłowym o nazwie Parquet i myślę, że korzyści są prawdopodobnie takie same – szybsze przetwarzanie danych, gdy potrzebujesz tylko zapytania do niewielkiego podzbioru dużej liczby kolumn. Miałem zapytanie działające na około 50 terabajtach plików Avro (format pliku zorientowany na wiersze) z 673 kolumnami, co zajęło około półtorej godziny w 140-węzłowym klastrze Hadoop. W przypadku Parkietu to samo zapytanie zajęło około 22 minut, ponieważ potrzebowałem tylko 5 kolumn. Jeśli masz niewielką liczbę kolumn lub używasz dużej części swoich kolumn, nie sądzę, aby kolumna z bazą danych miałaby istotną różnicę w porównaniu z kolumną zorientowaną na wiersz, ponieważ nadal będziesz musiał zasadniczo przeskanować wszystkie swoje dane. Wierzę, że w kolumnowych bazach danych kolumny są przechowywane osobno, podczas gdy w bazach zorientowanych na wiersze są przechowywane osobno. Twoje zapytanie będzie szybsze za każdym razem, gdy będziesz mógł odczytać mniej danych z dysku.