R to język i środowisko dla obliczeń statystycznych i grafiki. Jest to projekt GNU podobny do języka S i środowiska opracowanego w Bell Laboratories (dawniej AT&T, obecnie Lucent Technologies) przez Johna Chambersa i współpracowników. R można uznać za inną implementację S. Istnieje kilka ważnych różnic, ale wiele kodu napisanego dla przebiegów S niezmienionych pod R. R zapewnia szeroki zakres statystyczny (modelowanie liniowe i nieliniowe, klasyczne testy statystyczne, analiza szeregów czasowych, klasyfikacja, grupowanie,…) i techniki graficzne, i jest wysoce rozszerzalny. Język S jest często nośnikiem wyboru w badaniach metodologii statystycznej, a R zapewnia ścieżkę Open Source do uczestnictwa w tym działaniu. Jedną z mocnych stron R jest łatwość tworzenia dobrze zaprojektowanych wykresów o jakości publikacji, w tym symboli matematycznych i wzorów w razie potrzeby. Wiele uwagi poświęcono domyślnym ustawieniom niewielkich opcji graficznych, ale użytkownik zachowuje pełną kontrolę. R został stworzony przez Rossa Ihakę i Roberta Gentlemana, a teraz jest rozwijany przez zespół R Development Core Team. Środowisko R można łatwo rozszerzyć dzięki systemowi pakowania w CRAN. R jest dostępny jako Wolne Oprogramowanie na zasadach GNU Fundacji Wolnego Oprogramowania
Ogólna licencja publiczna w formie kodu źródłowego. Kompiluje i działa na wielu różnych platformach UNIX i podobnych systemach (w tym FreeBSD i Linux), Windows i Mac OS.
PYTANIA:
Programowe uruchamianie skryptu R.
Mam skrypt R, który generuje raport na podstawie bieżącej zawartości bazy danych. Ta baza danych stale się zmienia, a rekordy są dodawane / usuwane wiele razy każdego dnia. Jak mogę poprosić komputer, aby uruchamiał to codziennie o 4 rano, aby rano czekał na mnie aktualny raport? A może chcę, aby uruchomił się ponownie po dodaniu pewnej liczby nowych rekordów do bazy danych. Jak mogę to zautomatyzować? Powinienem wspomnieć, że korzystam z systemu Windows, ale mógłbym łatwo umieścić ten skrypt na moim komputerze z systemem Linux, jeśli uprości to ten proces.
ODPOWIEDZI:
W systemie Windows użyj harmonogramu zadań, aby ustawić uruchamianie zadania, na przykład codziennie o 4:00. Daje to wiele innych opcji dotyczących częstotliwości itp.
Jak mogę poprosić komputer, aby uruchamiał to codziennie o 4 rano, aby rano czekał na mnie aktualny raport? Możesz skonfigurować cronjob w systemie Linux. Są one uruchamiane o ustalonej godzinie, jeśli komputer jest włączony. Aby to zrobić, otwórz terminal i wpisz:
crontab -e
I dodaj:
00 4 * * * r źródło (/ home / FilePath /…/ myRscript.R)
Jakie są ograniczenia pamięci R.
Jedną z moich krytyk pedagogiki uczenia statystycznego (SL) jest brak uwzględnienia wydajności obliczeń w ocenie różnych technik modelowania. Z naciskiem na ładowanie i weryfikację krzyżową w celu dostrojenia / przetestowania modeli, SL wymaga dużej mocy obliczeniowej. Dodaj do tego osadzone ponowne próbkowanie
w technikach takich jak tworzenie worków i boosting, a masz widmo piekła obliczeniowego do nadzorowanego uczenia się dużych zbiorów danych. W rzeczywistości ograniczenia pamięci R nakładają dość surowe ograniczenia na rozmiar modeli, które można dopasować za pomocą najlepszych metod, takich jak losowe lasy. Chociaż SL dobrze wykonuje kalibrację wydajności modelu w stosunku do małych zestawów danych, dobrze byłoby zrozumieć wydajność w porównaniu z kosztem obliczeniowym większych danych. Jakie są ograniczenia pamięci R. i czy nakładają poważne ograniczenia na rozmiar modeli, które można dopasować przy użyciu najbardziej skutecznych metod, takich jak losowe lasy?
R wykonuje wszystkie obliczenia w pamięci systemu, tj. w pamięci RAM. Dlatego pojemność pamięci RAM jest bardzo ważnym ograniczeniem dla operacji intensywnie obliczeniowych w R. Po przezwyciężeniu tego ograniczenia dane są obecnie przechowywane w systemach HDFS, w których dane nie są ładowane do pamięci, a program jest zamiast tego uruchamiany, program przechodzi do danych i wykonuje operacje, pokonując w ten sposób ograniczenia pamięci.
RHadoop (https://github.com/RevolutionAnalytics/RHadoop/wiki) to złącze, którego szukasz. Jeśli chodzi o wpływ na algorytmy wymagające intensywnych obliczeń, losowe lasy / drzewa decyzyjne / zespoły na znacznej ilości danych (z mojego doświadczenia co najmniej 50 000 obserwacji) zajmują dużo pamięci i są znacznie powolne. Aby przyspieszyć ten proces, paralelizacja jest właściwą drogą, a paralelizacja jest z natury dostępna w Hadoop! Właśnie tam Hadoop jest naprawdę wydajny. Jeśli więc wybierasz metody złożone, które wymagają dużej mocy obliczeniowej i są wolne, warto wypróbować system HDFS, który zapewnia znaczną poprawę wydajności.
R wykonuje wszystkie obliczenia w pamięci, więc nie można wykonać operacji na zestawie danych większym niż dostępna ilość pamięci RAM. Istnieją jednak biblioteki umożliwiające przetwarzanie bigdata przy użyciu R i jedną z popularnych bibliotek do przetwarzania bigdata, takich jak Hadoop.
Błąd R przy użyciu pakietu tm (eksploracja tekstu)
Próbuję użyć pakietu tm do konwersji wektora ciągów tekstowych na element corpus. Mój kod wygląda mniej więcej tak Korpus (d1 $ Tak), gdzie d1 $ Tak jest czynnikiem ze 124 poziomami, z których każdy zawiera ciąg tekstowy. Na przykład d1 $ Tak [246] = „Abyśmy mogli wydostać łódź!” Otrzymuję następujący błąd: „Błąd: dziedziczy (x,„ Źródło ”) nie jest PRAWDA” Nie jestem pewien, jak temu zaradzić.
Musisz powiedzieć Corpusowi, jakiego źródła używasz. Wypróbuj:
Korpus (VectorSource (d1 $ Tak))
Czy musisz znormalizować dane podczas budowania drzew decyzyjnych przy użyciu R?
Nasz zestaw danych w tym tygodniu ma 14 atrybutów, a każda kolumna ma bardzo różne wartości. Jedna kolumna ma wartości poniżej 1, a druga kolumna ma wartości od trzech do czterech pełnych cyfr. Nauczyliśmy się normalizacji w zeszłym tygodniu i wygląda na to, że powinieneś normalizować dane, gdy mają one bardzo różne wartości. Czy w przypadku drzew decyzyjnych sprawa jest taka sama? Nie jestem tego pewien, ale czy normalizacja wpłynie na wynikowe drzewo decyzyjne z tego samego zestawu danych? Nie wydaje się tak, ale …
Żadna monotoniczna transformacja nie ma wpływu na najczęściej spotykane typy drzew decyzyjnych. Tak długo, jak zachowujesz porządek, drzewa decyzyjne są takie same (oczywiście przez to samo drzewo rozumiem tę samą strukturę decyzyjną, a nie te same wartości dla każdego testu w każdym węźle drzewa). Powodem tego jest to, jak działają zwykłe funkcje zanieczyszczenia. Aby znaleźć najlepszy podział, przeszukuje każdy wymiar (atrybut) punkt podziału, który jest w zasadzie klauzulą if, która grupuje wartości docelowe odpowiadające instancjom, których wartość testowa jest mniejsza niż wartość podziału, a po prawej wartości większe niż równe. Dzieje się tak w przypadku atrybutów numerycznych (co moim zdaniem jest twoim przypadkiem, ponieważ nie wiem, jak znormalizować atrybut nominalny). Teraz możesz zauważyć, że kryteria są mniejsze lub większe niż. Co oznacza, że rzeczywista informacja z atrybutów w celu znalezienia podziału (i całego drzewa) to tylko kolejność wartości. Co oznacza, że dopóki przekształcisz swoje atrybuty w taki sposób, że pierwotne uporządkowanie jest zarezerwowane, otrzymasz to samo drzewo. Nie wszystkie modele są niewrażliwe na tego rodzaju transformację. Na przykład modele regresji liniowej dają takie same wyniki, jeśli pomnożymy atrybut przez coś innego niż zero. Otrzymasz różne współczynniki regresji, ale przewidywana wartość będzie taka sama. Nie dzieje się tak, gdy weźmiesz dziennik tej transformacji. Na przykład w przypadku regresji liniowej normalizacja jest bezużyteczna, ponieważ zapewni ten sam wynik. Jednak nie jest tak w przypadku karanej regresji liniowej, takiej jak regresja kalenicy. W karanych regresjach liniowych do współczynników stosowane jest ograniczenie. Chodzi o to, że ograniczenie jest stosowane do sumy funkcji współczynników. Teraz, jeśli napompujesz atrybut, współczynnik zostanie spuszczony, co oznacza, że w końcu kara za ten współczynnik zostanie sztucznie zmodyfikowana. W takiej sytuacji normalizujesz atrybuty, aby każdy współczynnik był ograniczeniem „sprawiedliwie”. Mam nadzieję, że to pomoże
Wizualizuj poziomy wykres pola w R
Mam taki zestaw danych. Dane zostały zebrane za pomocą kwestionariusza i zamierzam przeprowadzić analizę danych eksploracyjnych.
windows <- c(“yes”, “no”,”yes”,”yes”,”no”)
sql <- c(“no”,”yes”,”no”,”no”,”no”)
excel <- c(“yes”,”yes”,”yes”,”no”,”yes”)
salary <- c(100,200,300,400,500 )
test<- as.data.frame (cbind(windows,sql,excel,salary),stringsAsFactors=TRUE)
test[,”salary”] <- as.numeric(as.character(test[,”salary”] ))
Mam zmienną wynikową (wynagrodzenie) w moim zbiorze danych i kilka zmiennych wejściowych (narzędzia). Zacznijmy od stworzenia fałszywego zestawu danych.
software = sample(c(“Windows”,”Linux”,”Mac”), n=100, replace=T)
salary = runif(n=100,min=1,max=100)
test = data.frame(software, salary)
To powinno stworzyć test ramki danych, który będzie wyglądał mniej więcej tak:
Pomiń wynagrodzenie za oprogramowanie blokowe
1 Windows 96,697217
2 Linux 29,770905
3 Windows 94.249612
4 Mac 71.188701
5 Linux 94,028326
6 Linux 7.482632
7 Mac 98,841689
8 komputerów Mac 81,152623
9 Windows 54,073761
10 Windows 1.707829
EDYCJA na podstawie komentarza Uwaga: jeśli dane nie istnieją już w powyższym formacie, można je zmienić na ten format. Weźmy ramkę danych podaną w pierwotnym pytaniu i załóżmy, że ramka danych nazywa się raw_test.
windows sql excel salary
1 yes no yes 100
2 no yes yes 200
3 yes no yes 300
4 yes no no 400
5 no no yes 500
Teraz, używając funkcji / metody topienia z pakietu przekształcania w R, najpierw utwórz test ramki danych (który zostanie wykorzystany do ostatecznego wydruku) w następujący sposób:
# use melt to convert from wide to long format
test = melt(raw_test,id.vars=c(“salary”))
# subset to only select where value is “yes”
test = subset(test, value == ‘yes’)
# replace column name from “variable” to “software”
names(test)[2] = “software”
Teraz otrzymasz test ramki danych, który wygląda następująco:
wartość oprogramowania wynagrodzeń
1 100 windows yes
3 300 windows yes
4 400 windows yes
7 200 sql yes
11 100 excel yes
12 200 excel yes
13 300 excel yes
15 500 excel yes
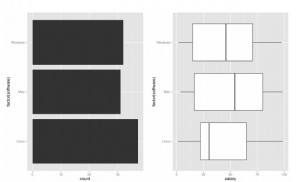
Po utworzeniu zestawu danych. Teraz wygenerujemy fabułę. Najpierw utwórz wykres słupkowy po lewej w oparciu o liczbę programów reprezentujących stopień wykorzystania.
p1 <- ggplot(test, aes(factor(software))) + geom_bar() + coord_flip()
Next, create the boxplot on the right.
p2 <- ggplot(test, aes(factor(software), salary)) + geom_boxplot() + coord_flip()
Na koniec umieść oba te wykresy obok siebie
require(‘gridExtra’)
grid.arrange(p1,p2,nrow=1)
To powinno stworzyć wykres taki jak:
Będziesz musiał utworzyć kolumnę zawierającą informacje o oprogramowaniu – na przykład nazwij to oprogramowanie, a kolumna wynagrodzenia ma odpowiednią pensję, więc coś w rodzaju
Wynagrodzenie za oprogramowanie
Software Salary
Microsoft 100
Microsoft 300
Microsoft 400
SQL 200
i tak dalej… możesz wydrukować poniższy kod
p <- ggplot(test, aes(factor(software), salary))
p + geom_boxplot() + coord_flip()
Testowanie oprogramowania dla Data Science w R.
Często używam Nosa, Toxa lub Unittesta podczas testowania mojego kodu python,
szczególnie gdy musi być zintegrowany z innymi modułami lub innymi częściami kodu. Jednak teraz, kiedy odkryłem, że używam R więcej niż pytona do modelowania i programowania ML. Uświadomiłem sobie, że tak naprawdę nie testuję mojego kodu R (a co ważniejsze, naprawdę nie wiem, jak to zrobić dobrze). Moje pytanie brzmi: jakie są dobre pakiety, które pozwalają testować kod R w podobny sposób, jak Nose, Tox lub Unittest w Pythonie. Docenione zostaną również dodatkowe odniesienia, takie jak samouczki. Punkty bonusowe za pakiety w R podobne do
- Hipoteza
lub
- Funkcja Forge
Pakiety do testów jednostkowych i testów asertywnych, które są aktywnie utrzymywane: Pakiety do testów jednostkowych
- test: więcej informacji na temat korzystania można znaleźć tutaj lub na github
- Uruchom: strona Cran
Pakiety dla asercji:
- twierdzą, że: informacje na github
- Asertywny: Asertywny ma wiele dostępnych podpakietów na wypadek, gdyby nie wszystkie były potrzebne. sprawdź Cran
- assertr: informacje na temat github
- gwarant: informacje na temat github
- tester: informacje na temat github
Jest kwestią preferencji, czego chcesz użyć do asercji. Przeczytaj tę stronę bioprzewodnika, aby uzyskać więcej informacji na temat różnicy między RUnit i tym testem.