PYTANIA:
Czy istnieje zamiennik małych wartości p w dużych zbiorach danych?
Jeśli w dużych zbiorach danych jest dużo małych wartości p, jakie jest porównywalne zastąpienie wartości p w danych z milionami próbek?
ODPOWIEDZI:
Nie ma zamiennika w ścisłym znaczeniu tego słowa. Zamiast tego powinieneś przyjrzeć się innym miarom. Inne miary, na które patrzysz, zależą od rodzaju problemu, który rozwiązujesz. Ogólnie rzecz biorąc, jeśli masz małą wartość p, rozważ także wielkość efektu. Może być bardzo istotne statystycznie, ale w praktyce bez znaczenia. Pomocne jest również podanie przedziału ufności wielkości efektu.
Kiedy wartości p są mylące? Gdy istnieje wiele zmiennych, które można przetestować pod kątem korelacji parami (na przykład), zastąpieniem jest użycie dowolnej z poprawek współczynnika fałszywych odkryć (w celu ograniczenia prawdopodobieństwa, że dane odkrycie jest fałszywe) lub współczynnika błędów rodzinnych ( aby ograniczyć prawdopodobieństwo jednego lub więcej fałszywych odkryć). Na przykład możesz użyć metody Holma – Bonferroniego. W przypadku dużej próbki, a nie wielu zmiennych, potrzebne jest coś innego. Jak powiedział Christopher, wielkość efektu jest sposobem na rozwiązanie tego problemu. Łącząc te dwie idee, możesz użyć przedziału ufności wokół wielkości efektu i zastosować fałsz korekta współczynnika wykrywania do wartości p przedziału ufności. Efekty, dla których nawet najniższa granica skorygowanego przedziału ufności jest wysoka, prawdopodobnie będą silnymi skutkami, niezależnie od ogromnego rozmiaru zbioru danych. Nie znam żadnego opublikowanego artykułu, który łączy w ten sposób przedziały ufności z fałszywą korektą wskaźnika odkryć, ale wydaje się, że jest to proste i intuicyjnie zrozumiałe podejście. Aby było to jeszcze lepsze, użyj nieparametrycznego sposobu szacowania przedziałów ufności. Zakładając, że rozkład może dać tutaj bardzo optymistyczne szacunki, a nawet dopasowanie rozkładu do danych prawdopodobnie będzie niedokładne. Ponieważ informacje o kształcie rozkładu poza krawędziami przedziału ufności pochodzą ze stosunkowo niewielkiej podpróbki danych, w tym miejscu naprawdę warto zachować ostrożność. Możesz użyć metody ładowania początkowego, aby uzyskać nieparametryczny przedział ufności.
Data Science jako socjolog?
Ponieważ bardzo interesuję się programowaniem i statystyką, Data Science wydaje mi się świetną ścieżką kariery – lubię obie dziedziny i chciałbym je połączyć. Niestety, studiowałem nauki polityczne z niestatystycznie brzmiącym mistrzem. Skupiłem się na statystykach w tym Master, odwiedzając opcjonalne kursy i pisząc pracę statystyczną na dość dużym zbiorze danych. Ponieważ prawie wszystkie stanowiska wymagają dyplomu z informatyki, fizyki lub innej dziedziny techniki, zastanawiam się, czy jest szansa, aby zostać naukowcem od danych, czy też powinienem porzucić ten pomysł.
Brakuje mi wiedzy na temat uczenia maszynowego, sql i hadoop, mając jednocześnie dość duże doświadczenie w informatyce i statystyce. Czy ktoś może mi powiedzieć, jak wykonalny jest mój cel zostania naukowcem danych?
Nauka o danych to termin, który jest używany tak samo luźno jak Big Data. Każdy ma zgrubne pojęcie, co rozumieją przez ten termin, ale jeśli spojrzysz na rzeczywiste zadania, obowiązki analityka danych będą się znacznie różnić w zależności od firmy. Analiza statystyczna mogłaby objąć całość obciążenia pracą na jednym stanowisku, a nawet nie uwzględniać innego. Nie chciałbym gonić za tytułem zawodowym jako takim. Jeśli jesteś zainteresowany tą dziedziną, połącz się w sieć (tak jak teraz) i znajdź dobre dopasowanie. Jeśli przeglądasz ogłoszenia o pracę, po prostu poszukaj tych, które podkreślają podstawy statystyki i informatyki. Hadoop i SQL są łatwe do zaznajomienia się z nimi, biorąc pod uwagę czas i motywację, ale chciałbym trzymać się obszarów, w których jesteś najsilniejszy i od tego zacząć.
Odpowiedz przez atak matematyczny Podejrzewam, że to zostanie zamknięte, ponieważ jest bardzo wąskie, ale moje 2 centy…
Data Science wymaga 3 umiejętności:
* Matematyka / statystyki
*Programowanie
* Wiedza domeny
Pokazanie wszystkich trzech może być bardzo trudne. Punkty 1 i 2 można oznaczyć stopniami, ale kierownik ds. rekrutacji, który może ich nie mieć, nie chce ufać dyplomowi sztuk wyzwolonych. Jeśli chcesz zająć się nauką o danych, najpierw zostań ekspertem domeny. Publikuj prognozy wyborcze. Jeśli masz rację, zacytuj je. Dzięki temu zostaniesz zauważony.
Jeśli posiadasz wiedzę o domenie na poziomie A+, nie potrzebujesz umiejętności programowania na poziomie A+, ale nauczysz się programowania na tyle, że nie potrzebujesz nikogo, kto będzie pobierał dane za Ciebie.
Zorientowany na naukę o danych zbiór danych / pytanie badawcze dla mgr statystyki
Praca dyplomowa
Chciałbym zbadać „naukę o danych”. Termin wydaje mi się trochę niejasny, ale spodziewam się, że będzie wymagał:
- uczenie maszynowe (zamiast tradycyjnych statystyk);
- wystarczająco duży zbiór danych, aby przeprowadzić analizy na klastrach.
Jakie są dobre zbiory danych i problemy, dostępne dla statystów z pewnym doświadczeniem programistycznym, których mogę użyć do zbadania dziedziny nauki o danych? Aby było to możliwie jak najbardziej zawężone, najlepiej byłoby, gdyby zawierały linki do otwartych, dobrze używanych zbiorów danych i przykładowych problemów.
Po prostu przejdź do kaggle.com; zapewni Ci to zajęcie przez długi czas. W przypadku otwartych danych dostępne jest repozytorium UC Irvine Machine Learning. W rzeczywistości istnieje cała witryna Stackexchange poświęcona temu;
Fundacja Sunlight to organizacja, która koncentruje się na otwieraniu i zachęcaniu do bezstronnej analizy danych rządowych. W naturze istnieje mnóstwo analiz, które można wykorzystać do porównań, oraz wiele różnych tematów. Dostarczają narzędzi i interfejsów API do uzyskiwania dostępu do danych i pomagają w udostępnianiu danych w miejscach takich jak data.gov. Ciekawym projektem jest Influence Explorer. Możesz tutaj uzyskać dane źródłowe, a także dostęp do danych w czasie rzeczywistym.
Możesz również rzucić okiem na jedno z naszych bardziej popularnych pytań: publicznie dostępne zbiory danych.
Czy masz tytuł magistra informatyki? Statystyka?
Czy „nauka o danych” będzie w centrum twojej pracy dyplomowej? Czy temat poboczny? Zakładam, że zajmujesz się statystyką i chcesz skoncentrować swoją pracę magisterską na problemie „nauki o danych”. Jeśli tak, to pójdę pod prąd i zasugeruję, aby nie rozpoczynać od zbioru danych lub metody ML. Zamiast tego powinieneś poszukać interesującego problemu badawczego jeśli jest to słabo poznane lub gdzie metody ML nie okazały się jeszcze skuteczne, lub gdzie istnieje wiele konkurencyjnych metod ML, ale żadna nie wydaje się lepsza od innych. Rozważmy to źródło danych: zbiór danych Stanford Large Network Dataset. Chociaż możesz wybrać jeden z tych zestawów danych, utwórz opis problemu, a następnie uruchom listę metdo ML
metody, to podejście naprawdę nie mówi zbyt wiele o tym, czym jest nauka o danych, i moim zdaniem nie prowadzi do bardzo dobrej pracy magisterskiej. Zamiast tego możesz zrobić to: poszukaj wszystkich artykułów naukowych, które używają ML w jakiejś określonej kategorii – np. Sieci współpracy (a.k.a. współautorstwo). Czytając każdy artykuł, spróbuj dowiedzieć się, co byli w stanie osiągnąć za pomocą każdej metody ML, a czego nie byli w stanie rozwiązać. Szczególnie szukaj ich sugestii dotyczących „przyszłych badań”. Może wszyscy używają tej samej metody, ale nigdy nie próbowali konkurować z metodami ML. A może nie weryfikują odpowiednio swoich wyników, a może zbiory danych są małe, a może ich pytania badawcze i hipotezy były uproszczone lub ograniczone. Najważniejsze: spróbuj dowiedzieć się, dokąd zmierza ta linia badań. Dlaczego w ogóle się tym przejmują? Co jest w tym ważnego? Gdzie i dlaczego napotykają trudności?
Najlepsze języki do obliczeń naukowych
Wydaje się, że w większości języków dostępna jest pewna liczba naukowych bibliotek obliczeniowych.
* Python ma Scipy
* Rust ma SciRust
* C ++ ma kilka, w tym ViennaCL i Armadillo
* Java ma Java Numerics i Colt, a także kilka innych
Nie wspominając o językach takich jak R i Julia, zaprojektowanych specjalnie do obliczeń naukowych. Przy tak wielu opcjach, jak wybrać najlepszy język do zadania? Dodatkowo, które języki będą najbardziej wydajne? Wydaje się, że Python i R mają największą przyczepność w przestrzeni, ale logicznie rzecz biorąc, język kompilowany wydaje się być lepszym wyborem. I czy coś kiedykolwiek przewyższy Fortran? Ponadto języki kompilowane mają zwykle akcelerację GPU, podczas gdy języki interpretowane, takie jak R i Python, nie. Co powinienem wziąć pod uwagę przy wyborze języka i które języki zapewniają najlepszą równowagę użyteczności i wydajności? Czy są też języki ze znaczącymi zasobami obliczeń naukowych, które przegapiłem?
To dość obszerne pytanie, więc nie jest to pełna odpowiedź, ale miejmy nadzieję, że może to pomóc w uzyskaniu ogólnych informacji na temat określenia najlepszego narzędzia do pracy, jeśli chodzi o naukę o danych. Generalnie mam stosunkowo krótką listę kwalifikacji, których szukam, jeśli chodzi o jakiekolwiek narzędzie w tej przestrzeni. W przypadkowej kolejności są to:
* Wydajność: Zasadniczo sprowadza się do tego, jak szybko język wykonuje mnożenie macierzy, ponieważ jest to mniej więcej najważniejsze zadanie w nauce o danych.
* Skalowalność: przynajmniej dla mnie osobiście sprowadza się to do łatwości budowania systemu rozproszonego. To jest miejsce, w którym języki takie jak Julia naprawdę świecą.
* Społeczność: w każdym języku naprawdę szukasz aktywnej społeczności, która może Ci pomóc, gdy utkniesz w używaniu dowolnego narzędzia, którego używasz. W tym miejscu Python wyprzedza większość innych języków.
* Elastyczność: nie ma nic gorszego niż ograniczenie przez język, którego używasz. Nie zdarza się to zbyt często, ale próba odwzorowania struktur grafowych w haskell jest notorycznym problemem, a Julia jest przepełniona wieloma problemami związanymi z architekturą kodu w wyniku bycia takim młodym językiem.
* Łatwość użytkowania: jeśli chcesz używać czegoś w większym środowisku, upewnij się, że konfiguracja jest prosta i może być zautomatyzowana. Nie ma nic gorszego niż konieczność skonfigurowania skomplikowanej wersji na pół tuzinie maszyn.
Jest mnóstwo artykułów na temat wydajności i skalowalności, ale generalnie będziesz się przyglądać różnicy wydajności wynoszącej może 5–10 razy między językami, co może mieć lub nie mieć znaczenia w zależności od konkretnej aplikacji. Jeśli chodzi o akcelerację GPU, cudamat jest naprawdę bezproblemowym sposobem na uruchomienie go z Pythonem, a biblioteka cuda ogólnie sprawiła, że akceleracja GPU jest znacznie bardziej dostępna niż kiedyś. Dwie podstawowe miary, których używam zarówno w odniesieniu do społeczności, jak i elastyczności, to spojrzenie na platformę menedżera pakietów językowych i pytania językowe w witrynie takiej jak SO. Jeśli istnieje wiele wysokiej jakości pytań i odpowiedzi, to dobry znak, że społeczność jest aktywna. Liczba pakietów i ogólna aktywność na tych pakietach również mogą być dobrym proxy dla tej metryki. Jeśli chodzi o łatwość użycia, jestem głęboko przekonany, że jedynym sposobem, aby to wiedzieć, jest samodzielne skonfigurowanie. Istnieje wiele przesądów związanych z wieloma narzędziami do nauki o danych, w szczególności takimi jak bazy danych i rozproszona architektura obliczeniowa, ale nie ma sposobu, aby naprawdę dowiedzieć się, czy coś jest łatwe, czy trudne do skonfigurowania i wdrożenia bez samodzielnego zbudowania.
Standaryzuj liczby dla wskaźników rankingowych
Próbuję uszeregować niektóre procenty. Mam liczniki i mianowniki dla każdego stosunku. Aby podać konkretny przykład, rozważ stosunek liczby absolwentów do liczby uczniów w szkole. Problem polega jednak na tym, że całkowita liczba uczniów różni się w dużym zakresie (1000-20000). Mniejszy
Szkoły wydają się mieć większy odsetek absolwentów, ale chcę go ujednolicić i nie pozwolić, aby wielkość szkoły wpływała na ranking. Czy jest na to sposób?
Matematycznie jest to stosunkowo proste. Najpierw dopasuj linię regresji do wykresu punktowego „całkowita liczba absolwentów” (y) vs „całkowita liczba studentów” (x). Prawdopodobnie zobaczysz opadającą linię, jeśli twoje twierdzenie jest poprawne (mniejsze szkoły kończą wyższy procent). Możesz zidentyfikować nachylenie i punkt przecięcia z osią y dla tej prostej, aby przekształcić ją w równanie y = mx + b, a następnie zrób trochę algebry, aby przekształcić równanie w znormalizowaną postać: „y / x = m + b / x”
Następnie, biorąc pod uwagę wszystkie współczynniki w danych, należy odjąć tę RHS:
współczynnik znormalizowany = (suma ocen / wszystkich uczniów) – (m + b / ogółem uczniów) Jeśli wynik jest pozytywny, to stosunek jest powyżej normy dla tej wielkości (tj. powyżej linii regresji), a jeśli jest ujemny, jest poniżej linia regresji. Jeśli chcesz mieć wszystkie liczby dodatnie, możesz dodać dodatnią stałą, aby przenieść wszystkie wyniki powyżej zera. Oto jak to zrobić matematycznie, ale sugeruję, abyś zastanowił się, czy z punktu widzenia analizy danych rozsądne jest znormalizowanie według wielkości szkoły. Zależy to od celu Twojej analizy, a konkretnie od tego, jak ten współczynnik jest analizowany w odniesieniu do innych danych.
Analiza wyników testów A / B, które nie mają rozkładu normalnego, przy użyciu niezależnego testu t
Mam zestaw wyników z testu A / B (jedna grupa kontrolna, jedna grupa cech), które nie pasują do rozkładu normalnego. W rzeczywistości dystrybucja bardziej przypomina dystrybucję Landau. Uważam, że niezależny test t wymaga, aby próbki miały przynajmniej w przybliżeniu rozkład normalny, co zniechęca mnie do stosowania testu t jako ważnej metody badania istotności. Ale moje pytanie brzmi: w którym momencie można powiedzieć, że test t nie jest dobrą metodą testowania istotności? Innymi słowy, jak można określić, jak wiarygodne są wartości p testu t, biorąc pod uwagę tylko zbiór danych?
Rozkład danych nie musi być normalny, to rozkład próbkowania musi być prawie normalny. Jeśli wielkość twojej próby jest wystarczająco duża, to rozkład próbkowania średnich z Rozkładu Landaua powinien być prawie normalny, ze względu na Centralne Twierdzenie Graniczne. Oznacza to, że powinieneś być w stanie bezpiecznie używać testu t ze swoimi danymi.
Przykład
Rozważmy ten przykład: załóżmy, że mamy populację z rozkładem lognormalnym z mu = 0 i sd = 0,5 (wygląda trochę podobnie do Landaua)
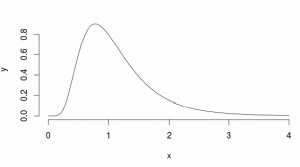
Więc próbkujemy 30 obserwacji 5000 razy z tego rozkładu za każdym razem obliczając średnią z próby
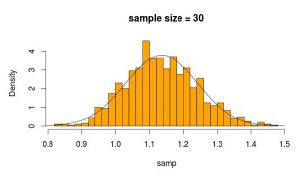
Wygląda całkiem normalnie, prawda? Jeśli zwiększymy wielkość próby, będzie to jeszcze bardziej widoczne
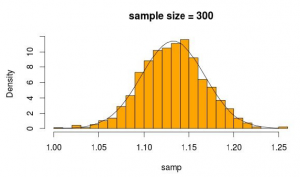
x = seq(0, 4, 0.05)
y = dlnorm(x, mean=0, sd=0.5)
plot(x, y, type=’l’, bty=’n’)
n = 30
m = 1000
set.seed(0)
samp = rep(NA, m)
for (i in 1:m) {
samp[i] = mean(rlnorm(n, mean=0, sd=0.5))
}
hist(samp, col=’orange’, probability=T, breaks=25, main=’sample size = 30′)
x = seq(0.5, 1.5, 0.01)
lines(x, dnorm(x, mean=mean(samp), sd=sd(samp)))
n = 300
samp = rep(NA, m)
for (i in 1:m) {
samp[i] = mean(rlnorm(n, mean=0, sd=0.5))
}
hist(samp, col=’orange’, probability=T, breaks=25, main=’sample size = 300′)
x = seq(1, 1.25, 0.005)
lines(x, dnorm(x, mean=mean(samp), sd=sd(samp)))J