PYTANIA:
Używając SVM jako klasyfikatora binarnego, czy etykieta punktu danych jest wybierana w drodze konsensusu?
Uczę się maszyn wektorów pomocniczych i nie jestem w stanie zrozumieć, w jaki sposób jest wybierana etykieta klasy dla punktu danych w klasyfikatorze binarnym. Czy jest wybierany w drodze konsensusu w odniesieniu do klasyfikacji w każdym wymiarze oddzielającej hiperpłaszczyzny?
ODPOWIEDZI:
Termin konsensus, o ile mi wiadomo, jest używany raczej w przypadkach, gdy masz więcej niż jedno źródło miernika / miary / wybór, na podstawie którego możesz podjąć decyzję. Aby wybrać możliwy wynik, wykonujesz średnią ocenę / konsensus dla dostępnej wartości. Nie dotyczy to SVM. Algorytm opiera się na optymalizacji kwadratowej, która maksymalizuje odległość od najbliższych dokumentów dwóch różnych klas, wykorzystując hiperpłaszczyznę do wykonania podziału.
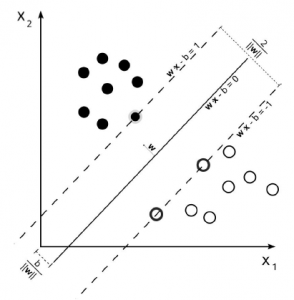
Tak więc jedynym konsensusem tutaj jest wynikowa hiperpłaszczyzna, obliczona na podstawie najbliższych dokumentów każdej klasy. Innymi słowy, klasy są przypisywane do każdego punktu poprzez obliczenie odległości od punktu do wyprowadzonej hiperpłaszczyzny. Jeśli odległość jest dodatnia, należy do określonej klasy, w przeciwnym razie należy do drugiej.
Wybierz algorytm klasyfikacji binarnej
Mam problem z klasyfikacją binarną:
* Około 1000 próbek w zestawie treningowym
* 10 atrybutów, w tym binarne, liczbowe i kategorialne
Który algorytm jest najlepszy do tego typu problemu?
Domyślnie zacznę od SVM (wstępna konwersja nominalnych wartości atrybutów na cechy binarne), ponieważ jest uważana za najlepszą dla stosunkowo czystych i niezakłóconych danych.
Trudno powiedzieć, nie wiedząc trochę więcej o swoim zbiorze danych i o tym, jak można go rozdzielić na podstawie wektora cech, ale prawdopodobnie sugerowałbym użycie ekstremalnego lasu losowego zamiast standardowych lasów losowych z powodu stosunkowo małego zestawu próbek. Ekstremalnie losowe lasy są bardzo podobne do standardowych lasów losowych z jednym wyjątkiem, że zamiast optymalizować podziały na drzewach, ekstremalnie losowe lasy powodują podziały losowo. Początkowo może się to wydawać negatywne, ale ogólnie oznacza to, że masz znacznie lepsze uogólnienie i szybkość, chociaż AUC na twoim zestawie treningowym jest prawdopodobnie być trochę gorszym. Regresja logistyczna jest również całkiem solidnym zakładem dla tego rodzaju zadań, chociaż przy waszej stosunkowo małej wymiarowości i małej wielkości próby obawiałbym się nadmiernego dopasowania. Możesz chcieć sprawdzić za pomocą K-Nearest Neighbors, ponieważ często działa bardzo dobrze przy małych wymiarach, ale zwykle nie radzi sobie zbyt dobrze ze zmiennymi kategorialnymi. Gdybym miał wybrać jeden, nie wiedząc więcej o problemie, z pewnością postawiłbym swoje zakłady na skrajnie losowy las, ponieważ jest bardzo prawdopodobne, że da ci dobre uogólnienie na tego rodzaju zestawach danych, a także lepiej radzi sobie z połączeniem danych liczbowych i kategorycznych niż większość innych metod.
W przypadku niskich parametrów, dość ograniczona wielkość próbki i regresja logistyczna klasyfikatora binarnego powinna być wystarczająco potężna. Możesz użyć bardziej zaawansowanego algorytmu, ale prawdopodobnie jest to przesada.
Gdy w mieszance są zmienne kategorialne, sięgam po Lasy losowych decyzji, ponieważ obsługuje ona zmienne kategorialne bezpośrednio, bez transformacji kodowania 1 z n. To powoduje utratę mniej informacji.
Personalizacja na dużą skalę – na użytkownika a modele globalne
Obecnie pracuję nad projektem, który skorzystałby na spersonalizowanych prognozach. Biorąc pod uwagę dokument wejściowy, zestaw dokumentów wyjściowych i historię zachowań użytkowników, chciałbym przewidzieć, które z dokumentów wyjściowych zostaną kliknięte. Krótko mówiąc, zastanawiam się, jakie jest typowe podejście do tego rodzaju problemu z personalizacją. Czy modele są szkolone dla każdego użytkownika, czy też pojedynczy model globalny bierze pod uwagę statystyki podsumowujące zachowanie użytkowników w przeszłości, aby pomóc w podjęciu decyzji? Modele na użytkownika nie będą dokładne, dopóki użytkownik nie będzie aktywny przez jakiś czas, podczas gdy większość modeli globalnych musi zostać ustalona jako wektor cech długości (co oznacza, że musimy mniej więcej skompresować strumień przeszłych zdarzeń do mniejszej liczby statystyk podsumowujących).
Odpowiedź na to pytanie będzie się bardzo różnić w zależności od rozmiaru i charakteru danych. Na wysokim poziomie można by pomyśleć o tym jako o szczególnym przypadku modeli wielopoziomowych; masz możliwość oszacowania modelu z pełnym pulowaniem (czyli uniwersalnym modelem, który nie rozróżnia użytkowników), modelami bez pulowania (osobny model dla każdego użytkownika) i częściowo połączonymi modelami (mieszanka tych dwóch) . Jeśli jesteś zainteresowany, naprawdę powinieneś przeczytać Andrew Gelman na ten temat. Możesz również myśleć o tym jako o problemie związanym z uczeniem się do rangi, który albo próbuje wytworzyć punktowe oszacowania przy użyciu pojedynczej funkcji, albo zamiast tego próbuje zoptymalizować jakąś listową funkcję straty (np. NDCG). Podobnie jak w przypadku większości problemów związanych z uczeniem maszynowym, wszystko zależy od rodzaju posiadanych danych, ich jakości, rzadkości i rodzajów funkcji, które możesz z nich wyodrębnić. Jeśli masz powody, by sądzić, że każdy użytkownik będzie dość wyjątkowy w swoim zachowaniu, możesz chcieć zbudować model dla każdego użytkownika, ale będzie to nieporęczne szybkie – i co robisz, gdy masz do czynienia z nowy użytkownik?
Jakie metody klasyfikacyjne niezwiązane ze szkoleniem są dostępne?
Próbuję dowiedzieć się, które metody klasyfikacji, które nie wykorzystują fazy treningowej, są dostępne. Scenariusz jest klasyfikacją opartą na ekspresji genów, w której masz macierz ekspresji genów m genów (cech) i n próbek (obserwacje). Podaje się również podpis dla każdej klasy (jest to lista funkcji, które należy wziąć pod uwagę w celu zdefiniowania, do której klasy należy próbka). Aplikacja (nie będąca szkoleniem) jest metodą przewidywania najbliższego szablonu. W tym przypadku obliczana jest odległość cosinusowa między każdą próbką a każdą sygnaturą (na wspólnym zbiorze cech). Następnie każda próbka jest przypisywana do najbliższej klasy (porównanie próby z klasą skutkuje mniejszą odległością). W tym przypadku nie są potrzebne już sklasyfikowane próbki. Innym zastosowaniem (treningiem) jest metoda kNN, w której mamy zestaw już oznaczonych próbek. Następnie każda nowa próbka jest oznaczana w zależności od tego, jak oznaczono k najbliższych próbek. Czy istnieją inne metody niezwiązane z treningiem?
Pytasz o uczenie się oparte na instancjach. Metoda k-Nearest Neighbors (kNN) wydaje się być najpopularniejszą z tych metod i ma zastosowanie w wielu różnych dziedzinach problemowych. Innym ogólnym typem uczenia się opartego na instancjach jest modelowanie analogiczne, które wykorzystuje instancje jako przykłady do porównania z nowymi danymi.
Odniosłeś się do kNN jako aplikacji, która wykorzystuje szkolenie, ale to nie jest poprawne (wpis w Wikipedii, do którego jesteś podłączony, jest nieco mylący). Tak, istnieją „przykłady szkoleniowe” (oznaczone jako wystąpienia), ale klasyfikator nie uczy się / trenuje na podstawie tych danych. Są one raczej używane tylko wtedy, gdy rzeczywiście chcesz sklasyfikować nową instancję, dlatego jest ona uważana za „leniwego” ucznia. Zauważ, że metoda przewidywania najbliższego szablonu, o której wspominasz, jest formą kNN z k = 1 i odległością cosinusową jako miarą odległości.
Jestem początkującym w uczeniu maszynowym, więc wybaczcie mi ten prosty opis, ale wygląda na to, że możesz użyć modelowania tematycznego, takiego jak utajona analiza Dirichleta (LDA). Jest to algorytm szeroko stosowany do klasyfikowania dokumentów według tematów, których dotyczą, na podstawie znalezionych słów i względnej częstotliwości tych słów w całym korpusie. Poruszam to głównie dlatego, że w LDA nie ma potrzeby wcześniejszego definiowania tematów. Ponieważ strony pomocy w LDA są głównie napisane do analizy tekstu, analogia, której użyłbym, aby zastosować ją do twojego pytania, jest następująca: – Traktuj każdą ekspresję genu lub cechę jako “ słowo ” (czasami nazywane tokenem w typowe aplikacje do klasyfikacji tekstu LDA) – Traktuj każdą próbkę jak dokument (tj. zawiera zestaw słów lub wyrażeń genów) – Traktuj podpisy jako istniejące wcześniej tematy Jeśli się nie mylę, LDA powinno podać ważone prawdopodobieństwa dla każdego temat, jak mocno jest on obecny w każdym dokumencie.
Jak zdefiniować niestandardową metodologię ponownego próbkowania
Używam projektu eksperymentalnego, aby przetestować solidność różnych metod klasyfikacji, a teraz szukam prawidłowej definicji takiego projektu. Tworzę różne podzbiory pełnego zbioru danych, wycinając kilka próbek. Każdy podzbiór jest tworzony niezależnie od innych. Następnie uruchamiam każdą metodę klasyfikacji na każdym podzbiorze. Na koniec oceniam dokładność każdej metody jako liczbę klasyfikacji podzbiorów zgodnych z klasyfikacją w pełnym zbiorze danych. Na przykład:
Classification-full 1 2 3 2 1 1 2
Classification-subset1 1 2 2 3 1
Classification-subset2 2 3 1 1 2…
Accuracy 1 1 1 1 0.5 1 1
Czy istnieje poprawna nazwa tej metodologii? Myślałem, że to może podlegać bootstrapowi, ale nie jestem tego pewien.
Losowe podpróbkowanie wydaje się odpowiednie, ładowanie początkowe jest nieco bardziej ogólne, ale także poprawne.
Wypaczone dane wieloklasowe
Mam zbiór danych zawierający ~ 100 000 próbek z 50 klas. Używam SVM z jądrem RBF do trenowania i przewidywania nowych danych. Problem polega jednak na tym, że zbiór danych jest wypaczony w kierunku różnych klas.
Na przykład Class 1 – 30 (~3% each), Class 31 – 45 (~0.6% each), Class 46 – 50 (~0.2% each)
Widzę, że model bardzo rzadko przewiduje klasy, które występują rzadziej w zbiorze uczącym, mimo że zbiór testowy ma taki sam rozkład klas jak zbiór uczący. Zdaję sobie sprawę, że istnieją techniki takie jak „undersampling”, w których klasa większości jest zmniejszana do klasy podrzędnej. Czy ma to jednak zastosowanie tutaj, gdzie jest tak wiele różnych klas? Czy istnieją inne metody, które pomogą rozwiązać ten przypadek?
Sugerowałbym użycie biblioteki libsvm, która ma już zaimplementowane regulowane wagi klas. Zamiast replikować próbki uczące, modyfikuje się parametr C dla różnych klas w optymalizacji SVM. Na przykład, jeśli twoje dane mają 2 klasy, a pierwsza klasa to tylko 10% danych, możesz wybrać wagi klas na 10 i 1 odpowiednio dla klasy 1 i 2. Dlatego naruszenia marginesów pierwszej klasy kosztowałyby 10 razy więcej niż naruszenia marginesów dla drugiej klasy, a dokładności dla poszczególnych klas byłyby bardziej zrównoważone.
Nie jestem ekspertem w używaniu maszyn SVM, ale zwykle (jeśli używasz biblioteki uczenia maszynowego, takiej jak scikit-learn Pythona lub libsvm w języku R, jest odpowiednio parametr class_weight lub class.weights. Lub jeśli używasz Bayesa klasyfikator, weźmiesz pod uwagę to „pochylenie” poprzez „wcześniejsze (klasowe) prawdopodobieństwa” P (ωj)
Podobieństwo cosinusowe a iloczyn skalarny jako metryki odległości
Wygląda na to, że podobieństwo cosinusowe dwóch cech jest po prostu ich iloczynem skalarnym skalowanym przez iloczyn ich wielkości. Kiedy podobieństwo cosinusowe jest lepszą miarą odległości niż iloczyn skalarny? To znaczy. Czy iloczyn skalarny i podobieństwo cosinusa mają różne mocne lub słabe strony w różnych sytuacjach?
Myśl geometrycznie. Podobieństwo cosinusowe dba tylko o różnicę kątów, podczas gdy iloczyn skalarny dba o kąt i wielkość. Jeśli znormalizujesz dane, aby miały tę samą wielkość, te dwa są nie do odróżnienia. Czasami pożądane jest zignorowanie wielkości, stąd podobieństwo cosinusowe jest dobre, ale jeśli wielkość odgrywa rolę, iloczyn skalarny byłby lepszy jako miara podobieństwa. Zwróć uwagę, że żaden z nich nie jest „miarą odległości”.
Masz rację, podobieństwo cosinusowe ma wiele wspólnego z iloczynem skalarnym wektorów. Rzeczywiście, jest to iloczyn skalarny skalowany według wielkości. Ze względu na skalowanie jest znormalizowany między 0 a 1. CS jest preferowane, ponieważ uwzględnia zmienność danych i względne częstotliwości cech. Z drugiej strony, zwykły iloczyn skalarny jest trochę „tańszy” (pod względem złożoności i implementacji).
Chciałbym dodać jeszcze jeden wymiar do odpowiedzi udzielonych powyżej. Zwykle używamy podobieństwa cosinusowego w przypadku dużego tekstu, ponieważ nie zaleca się używania macierzy odległości na akapitach danych. A także, jeśli zamierzasz, aby twoja klaster była szeroka, będziesz mieć tendencję do podobieństwa cosinusowego, ponieważ oddaje ogólne podobieństwo. Na przykład, jeśli masz teksty, które mają maksymalnie dwa lub trzy słowa, uważam, że użycie podobieństwa cosinusowego nie zapewnia precyzji, jaką uzyskuje się za pomocą metryki odległości.
Który typ weryfikacji krzyżowej najlepiej pasuje do problemu klasyfikacji binarnej
Zbiór danych wygląda następująco:
25000 obserwacji do 15 predyktorów różnych typów: numeryczna, wieloklasowa jakościowa, binarna zmienna docelowa jest binarna Która metoda walidacji krzyżowej jest typowa dla tego typu problemów? Domyślnie używam K-Fold. Ile fałd wystarczy w tym przypadku? (Jednym z modeli, których używam, jest losowy las, który jest czasochłonny…)
Najlepsze wyniki osiągniesz, jeśli zechcesz zbudować fałdy tak, aby każda zmienna (a co najważniejsze zmienna docelowa) była w przybliżeniu identyczna w każdym fałdzie. Nazywa się to, w przypadku zastosowania do zmiennej docelowej, warstwowym k-krotnością. Jednym podejściem jest zgrupowanie danych wejściowych i upewnienie się, że każdy fałd zawiera taką samą liczbę wystąpień z każdego klastra, proporcjonalną do ich rozmiaru.
Myślę, że w twoim przypadku 10-krotne CV będzie OK. Myślę, że ważniejsze jest zrandomizowanie procesu walidacji krzyżowej niż wybranie idealnej wartości k. Powtórz więc proces CV kilka razy losowo i oblicz wariancję wyniku klasyfikacji, aby określić, czy wyniki są wiarygodne, czy nie.
Jaka jest różnica między klasyfikacją tekstu a modelami tematycznymi?
Znam różnicę między grupowaniem a klasyfikacją w uczeniu maszynowym, ale nie rozumiem różnicy między klasyfikacją tekstu a modelowaniem tematycznym dokumentów. Czy mogę użyć modelowania tematu na dokumentach, aby zidentyfikować temat? Czy mogę użyć metod klasyfikacji, aby sklasyfikować tekst w tych dokumentach?
Klasyfikacja tekstu
Daję ci kilka dokumentów, z których każdy ma dołączoną etykietę. Proszę was, abyście się dowiedzieli, dlaczego waszym zdaniem treść dokumentów otrzymała te etykiety na podstawie ich słów. Następnie daję Ci nowe dokumenty i pytam, jaka powinna być etykieta dla każdego z nich. Etykiety mają dla mnie znaczenie, niekoniecznie dla ciebie.
Modelowanie tematyczne
Daję ci kilka dokumentów bez etykiet. Proszę o wyjaśnienie, dlaczego dokumenty zawierają takie same słowa, jak te, które mają, poprzez wskazanie niektórych tematów, o których każdy „dotyczy”. Mówisz mi o tematach, mówiąc mi, ile z każdego z nich znajduje się w każdym dokumencie, a ja decyduję, jakie tematy
„Podły”, jeśli cokolwiek. Musiałbyś wyjaśnić, co ja, „określ jeden temat” lub „sklasyfikuj tekst”.
Ale nie wiem, jaka jest różnica między klasyfikacją tekstu a modelami tematycznymi w dokumentach Klasyfikacja tekstów jest formą nadzorowanego uczenia się – zestaw możliwych zajęć jest z góry znany / zdefiniowany i nie ulega zmianie. Modelowanie tematyczne jest formą uczenia się bez nadzoru (podobną do grupowania) – zbiór możliwych tematów to nieznane apriori. Są zdefiniowane jako część generowania modeli tematycznych. W przypadku niedeterministycznego algorytmu, takiego jak LDA, za każdym razem otrzymasz inne tematy uruchamiasz algorytm. Klasyfikacja tekstów często obejmuje wzajemnie wykluczające się klasy – należy je traktować jako zbiorniki. Ale nie musi – biorąc pod uwagę odpowiedni rodzaj oznaczonych danych wejściowych, można ustawić serię niewykluczających się wzajemnie klasyfikatorów binarnych. Modelowanie tematyczne generalnie nie wyklucza się wzajemnie – ten sam dokument może mieć rozkład prawdopodobieństwa rozłożony na wiele tematów. Ponadto istnieją hierarchiczne metody modelowania tematów itp. Czy mogę również użyć modelu tematu dla dokumentów, aby później zidentyfikować jeden temat. Czy mogę użyć klasyfikacji do sklasyfikowania tekstu w tych dokumentach? Jeśli pytasz, czy możesz wziąć wszystkie dokumenty przypisane do jednego tematu przez algorytm modelowania tematu, a następnie zastosować klasyfikator do tej kolekcji, to tak, z pewnością możesz to zrobić. Nie jestem jednak pewien, czy to ma sens – jako minimum musisz wybrać próg rozkładu prawdopodobieństwa tematu, powyżej którego uwzględnisz dokumenty w Twojej kolekcji (zwykle 0,05-0,1). Czy możesz rozwinąć swój przypadek użycia? Przy okazji, dostępny jest świetny samouczek dotyczący modelowania tematycznego przy użyciu biblioteki MALLET dla języka Java, dostępny tutaj: Pierwsze kroki z modelowaniem tematycznym i MALLET
Modele tematyczne są zwykle bez nadzoru. Istnieją również „nadzorowane modele tematyczne”; ale nawet wtedy próbują modelować tematy w ramach zajęć.
Na przykład. możesz mieć klasę „piłka nożna”, ale w ramach tej klasy mogą istnieć tematy związane z określonymi meczami lub drużynami. Wyzwanie związane z tematami polega na tym, że zmieniają się one w czasie; rozważ powyższy przykład meczów. Takie tematy mogą się pojawić i ponownie zniknąć.
Różnica między tf-idf i tf z Random Forests
Pracuję nad problemem klasyfikacji tekstu, używając Random Forest jako klasyfikatorów i podejścia bag-of-words. Używam podstawowej implementacji Random Forests (tej obecnej w scikit), która tworzy warunek binarny dla pojedynczej zmiennej przy każdym podziale. Biorąc to pod uwagę, czy istnieje różnica między używaniem prostych cech tf (częstotliwości terminów). gdzie każde słowo ma przypisaną wagę, która reprezentuje liczbę wystąpień w dokumencie lub tf-idf (częstotliwość terminu * odwrotna częstotliwość dokumentu), gdzie częstotliwość terminu jest również mnożona przez wartość, która reprezentuje stosunek całkowitej liczby dokumentów i liczbę dokumentów zawierających słowo)? Moim zdaniem nie powinno być żadnej różnicy między tymi dwoma podejściami, ponieważ jedyną różnicą jest współczynnik skalowania na każdej funkcji, ale ponieważ podział odbywa się na poziomie pojedynczych cech, nie powinno to robić różnicy.
Czy mam rację w swoim rozumowaniu?
Drzewa decyzyjne (a tym samym losowe lasy) są niewrażliwe na monotoniczne przekształcenia cech wejściowych. Ponieważ mnożenie przez ten sam współczynnik jest monotonną transformacją, założyłbym, że w przypadku Losowych Lasów rzeczywiście nie ma różnicy. Jednak w końcu możesz rozważyć użycie innych klasyfikatorów, które nie mają tej właściwości, więc nadal może mieć sens użycie całego TF * IDF.
Klasyfikacja dokumentów: tf-idf przed czy po filtrowaniu funkcji?
Mam projekt klasyfikacji dokumentów, w którym pobieram zawartość witryny, a następnie przypisuję do witryny jedną z wielu etykiet zgodnie z zawartością. Dowiedziałem się, że tf-idf może być do tego bardzo przydatne. Jednak nie byłem pewien, kiedy dokładnie go użyć. Zakładając, że strona internetowa zajmująca się określonym tematem wielokrotnie o tym wspomina, był to mój obecny proces:
- Pobierz zawartość witryny i przeanalizuj, aby znaleźć zwykły tekst
- Normalizuj i powstrzymuj zawartość
- Tokenizacja do unigramów (może też bigramów)
- Pobierz liczbę wszystkich unigramów dla danego dokumentu, filtrując słowa o małej długości i małej liczbie występujących słów
- Wytrenuj klasyfikator, taki jak NaiveBayes, na wynikowym zbiorze
Moje pytanie jest następujące: gdzie pasowałby tu tf-idf? Przed
normalizowanie / wyprowadzanie? Po normalizacji, ale przed tokenizacją? Po tokenizacji?
Każdy wgląd byłby bardzo mile widziany.
Po bliższym przyjrzeniu się, myślę, że mogłem mieć nieporozumienie co do tego, jak działa TF-IDF. W powyższym kroku 4, który opisuję, czy musiałbym od razu wprowadzić całość moich danych do TF-IDF? Jeśli na przykład moje dane są następujące:
[({tokenized_content_site1}, category_string_site1),
({tokenized_content_site2}, category_string_site2),
…
({tokenized_content_siten}, category_string_siten)}]
Tutaj najbardziej zewnętrzna struktura jest listą zawierającą krotki, zawierającą słownik (lub hashmap) i ciąg. Czy musiałbym od razu wprowadzić całość tych danych do kalkulatora TF-IDF, aby osiągnąć pożądany efekt? W szczególności patrzyłem na TfidfVectorizer scikit-learn, aby to zrobić, ale jestem trochę niepewny co do jego użycia, ponieważ przykłady są dość rzadkie.
Jak to opisałeś, krok 4 to miejsce, w którym chcesz użyć TF-IDF. Zasadniczo TD-IDF policzy każdy termin w każdym dokumencie i przypisze punktację, biorąc pod uwagę względną częstotliwość w całym zbiorze dokumentów. Brakuje jednak jednego dużego kroku w procesie: dodawania adnotacji do zestawu treningowego. Zanim wytrenujesz klasyfikator, musisz ręcznie dodać adnotacje do próbki danych etykietami, które chcesz mieć możliwość automatycznego stosowania za pomocą klasyfikatora. Aby to wszystko ułatwić, możesz rozważyć użycie klasyfikatora Stanford. To wykona wyodrębnianie cech i zbuduje model klasyfikatora (obsługujący kilka różnych algorytmów uczenia maszynowego), ale nadal będziesz musiał ręcznie dodawać adnotacje do danych szkoleniowych.
K-Nearest Neighbors
Czy algorytm k-najbliższego sąsiada jest klasyfikatorem dyskryminacyjnym czy generującym? Po raz pierwszy pomyślałem o tym, że jest generatywny, ponieważ faktycznie używa twierdzenia Bayesa do obliczenia późniejszego. Szukając dalej tego, wydaje się, że jest to model dyskryminacyjny, ale nie mogłem znaleźć wyjaśnienia. Czy więc KNN jest przede wszystkim dyskryminujący? A jeśli tak, czy to dlatego, że nie modeluje wyprzedzeń ani prawdopodobieństwa?
Zobacz podobną odpowiedź tutaj. Aby wyjaśnić, k- najbliższy sąsiad jest klasyfikatorem dyskryminacyjnym. Różnica między klasyfikatorem generatywnym a dyskryminacyjnym polega na tym, że pierwszy modeluje wspólne prawdopodobieństwo, podczas gdy drugi modeluje prawdopodobieństwo warunkowe (późniejsze), zaczynając od poprzedniego. W przypadku najbliższych sąsiadów modelowane jest prawdopodobieństwo warunkowe klasy dla danego punktu danych. Aby to zrobić, należy zacząć od wcześniejszego prawdopodobieństwa na zajęciach.
Drzewo decyzyjne czy regresja logistyczna?
Pracuję nad problemem klasyfikacyjnym. Mam zbiór danych zawierający równą liczbę zmiennych kategorialnych i ciągłych. Skąd mam wiedzieć, jakiej techniki użyć? między drzewem decyzyjnym a regresją logistyczną? Czy słuszne jest założenie, że regresja logistyczna będzie bardziej odpowiednia dla zmiennej ciągłej, a drzewo decyzyjne będzie bardziej odpowiednie dla zmiennej ciągłej + jakościowej?
Krótko mówiąc: rób to, co powiedział @untledprogrammer, wypróbuj oba modele i sprawdź krzyżowo, aby pomóc wybrać jeden. Zarówno drzewa decyzyjne (w zależności od implementacji, np. C4.5), jak i regresja logistyczna powinny dobrze radzić sobie z danymi ciągłymi i kategorialnymi. W przypadku regresji logistycznej warto zakodować fikcyjnie zmienne kategorialne.
Jak wspomniał @untitledprogrammer, trudno jest z góry ustalić, która technika będzie lepiej oparta po prostu na typie posiadanych funkcji, ciągłych lub innych. To naprawdę zależy od konkretnego problemu i posiadanych danych. Należy jednak pamiętać, że model regresji logistycznej szuka pojedynczej liniowej granicy decyzyjnej w przestrzeni cech, podczas gdy drzewo decyzyjne zasadniczo dzieli przestrzeń funkcji na półprzestrzenie przy użyciu liniowych granic decyzyjnych wyrównanych do osi. Efekt netto jest taki, że masz nieliniową granicę decyzyjną, prawdopodobnie więcej niż jedną. Jest to przyjemne, gdy punktów danych nie można łatwo oddzielić pojedynczą hiperpłaszczyzną, ale z drugiej strony drzewa decyzyjne są tak elastyczne, że mogą być podatne na nadmierne dopasowanie. Aby temu zaradzić, możesz spróbować przycinania. Regresja logistyczna jest zwykle mniej podatna (ale nie odporna!) Na nadmierne dopasowanie. Na koniec kolejną kwestią do rozważenia jest to, że drzewa decyzyjne mogą automatycznie uwzględniać interakcje między zmiennymi, np. jeśli masz dwie niezależne funkcje i. W przypadku regresji logistycznej musisz ręcznie dodać te terminy interakcji samodzielnie.
Musisz więc zadać sobie pytanie: jaki rodzaj granicy decyzyjnej ma większy sens w twoim konkretnym problemie? jak chcesz zrównoważyć odchylenie i wariancję? czy istnieją interakcje między moimi funkcjami?
Oczywiście zawsze dobrze jest po prostu wypróbować oba modele i przeprowadzić weryfikację krzyżową. To xy pomoże ci dowiedzieć się, który z nich bardziej przypomina lepszy błąd generalizacji.
Spróbuj użyć zarówno drzew regresyjnych, jak i decyzyjnych. Porównaj skuteczność każdej techniki, używając 10-krotnej weryfikacji krzyżowej. Trzymaj się tego o wyższej wydajności. Trudno byłoby ocenić, która metoda byłaby lepsza, wiedząc, że zbiór danych jest ciągły i / lub kategoryczny.