Pomysły na projekty Data Science
Nie wiem, czy to właściwe miejsce, aby zadać to pytanie, ale moim zdaniem najwłaściwszym miejscem powinna być społeczność poświęcona Data Science. Właśnie zacząłem od nauki o danych i uczenia maszynowego. Szukam długoterminowych pomysłów na projekty, nad którymi mógłbym pracować około 8 miesięcy. Połączenie nauki o danych i uczenia maszynowego byłoby świetne. Projekt wystarczająco duży, aby pomóc mi zrozumieć podstawowe koncepcje, a także wdrożyć je w tym samym czasie, byłby bardzo korzystny. Spróbowałbym przeanalizować i rozwiązać jeden lub więcej problemów opublikowanych na Kaggle Competitions (https://www.kaggle.com/competitions). Zwróć uwagę, że konkursy są pogrupowane według ich oczekiwanej złożoności, od 101 (na dole listy) do Badań i wyróżnionych (na górze listy). Pionowy pasek oznaczony kolorem to wizualna wskazówka dotycząca grupowania. Możesz ocenić czas, jaki możesz poświęcić na projekt, dostosowując oczekiwany czas trwania odpowiednich zawodów w oparciu o swoje umiejętności i doświadczenie. Szereg pomysłów na projekty związane z nauką o danych można znaleźć, przeglądając następujące pozycje
Strona internetowa Coursolve: https://www.coursolve.org/browse-needs?
zapytanie = Data% 20Science. Jeśli masz umiejętności i chęć pracy nad prawdziwym projektem nauki o danych, skupiającym się na skutkach społecznych, odwiedź stronę projektów DataKind: http://www.datakind.org/projects. Więcej projektów
z naciskiem na wpływy społeczne można znaleźć na stronie internetowej organizacji Data Science for Social Good: http://dssg.io/projects. Strona Science Project Ideas w witrynie My NASA Data wygląda jak inne miejsce, w którym można znaleźć inspirację: http://mynasadata.larc.nasa.gov/804-2. Jeśli chcesz korzystać z otwartych danych, ta długa lista aplikacji na Data.gov może dostarczyć Ci interesujących pomysłów na projekty z zakresu nauki o danych: http://www.data.gov/applications
Weź coś ze swojego codziennego życia. Stwórz predyktor korków w swoim regionie, spersonalizuj rekomendację muzyczną, przeanalizuj rynek samochodowy itp. Wybierz prawdziwy problem, który chcesz rozwiązać – to nie tylko zapewni Ci motywację, ale także sprawi, że przejdziesz przez cały krąg rozwoju od gromadzenia danych do testowania hipotez. Wprowadzenie do kursu Data Science, który jest prowadzony na Coursera, obejmuje teraz rzeczywiste zadania projektowe, w których firmy publikują swoje problemy, a studenci są zachęcani do ich rozwiązywania. Odbywa się to za pośrednictwem coursolve.com. Przewidując następny stan chorobowy na podstawie przeszłych stanów w danych roszczeniowych, jestem, co prawda, bardzo nowy w nauce o danych. Spędziłem mniej więcej ostatnie 8 miesięcy, ucząc się jak najwięcej o tej dziedzinie i jej metodach. Mam problemy z wyborem metod, które mam zastosować. Obecnie pracuję z dużym zbiorem danych o roszczeniach z tytułu ubezpieczenia zdrowotnego, który obejmuje niektóre roszczenia laboratoryjne i farmaceutyczne. Najbardziej spójne informacje w zbiorze danych składają się jednak z diagnozy (ICD-9CM) i kodów procedur (CPT, HCSPCS, ICD-9CM). Moje cele to:
- Zidentyfikować najbardziej wpływowe stany prekursorowe (choroby współistniejące) dla schorzeń, takich jak przewlekła choroba nerek;
- Określić prawdopodobieństwo (lub prawdopodobieństwo), że u pacjenta wystąpi stan chorobowy na podstawie warunków, jakie miał w przeszłości;
- Zrób to samo, co 1 i 2, ale z procedurami i / lub diagnozami.
- Najlepiej, aby wyniki były interpretowane przez lekarza
Przyjrzałem się takim rzeczom, jak materiały Milestone Heritage Health Prize i wiele się z nich nauczyłem, ale koncentrują się one na przewidywaniu hospitalizacji. Rzuciłem na ten problem szereg algorytmów (losowe lasy, regresja logistyczna, CART, regresje Coxa) i było to niesamowite doświadczenie edukacyjne. Nie byłem w stanie zdecydować, co „działa” lub „nie działa”, jeśli wiesz, co mam na myśli. Mam wystarczająco dużo wiedzy i umiejętności, by dać się zwieść własnej ekscytacji i naiwności; to, czego potrzebuję, to być w stanie ekscytować się czymś prawdziwym. Oto moje pytania: jakie metody Twoim zdaniem działają dobrze w przypadku takich problemów? Jakie zasoby byłyby najbardziej przydatne do poznania zastosowań i metod nauki o danych w służbie zdrowia i medycynie klinicznej?
Aby dodać tabelę tekstową: PChN jest stanem docelowym, „przewlekła choroba nerek”, „.any” oznacza, że doszło do tego stanu w dowolnym momencie, „.isbefore.ckd” oznacza, że mieli ten stan przed pierwszą diagnozą PChN. Pozostałe skróty odpowiadają innym stanom określonym przez zgrupowania kodów ICD-9CM. To grupowanie występuje w języku SQL podczas procesu importu. Każda zmienna, z wyjątkiem patient_age, jest binarna.
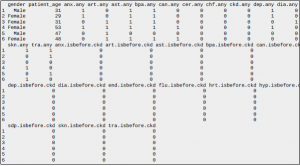
aby dodać przykładową ramkę danych:
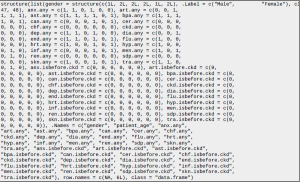
Nigdy nie pracowałem z danymi medycznymi, ale z ogólnego rozumowania powiedziałbym, że relacje między zmiennymi w opiece zdrowotnej są dość skomplikowane. Różne modele, takie jak losowe lasy, regresja itp., Mogą uchwycić tylko część relacji i zignorować inne. W takich okolicznościach sensowne jest zastosowanie ogólnej analizy statystycznej i modelowania. Na przykład, pierwszą rzeczą, którą bym zrobił, było znalezienie korelacji między możliwymi stanami prekursorowymi a diagnozami. Na przykład. w jakim procencie przypadków przewlekła choroba nerek była poprzedzona długą grypą? Jeśli jest wysoki, nie zawsze oznacza to przyczynowość, ale daje całkiem niezłe do myślenia i pomaga lepiej zrozumieć relacje między różnymi stanami. Kolejnym ważnym krokiem jest wizualizacja danych. Czy PChN występuje częściej u mężczyzn niż u kobiet? A co z ich miejscem zamieszkania? Jaki jest rozkład przypadków CKD według wieku? Trudno jest uchwycić duży zbiór danych jako zbiór liczb, a wykreślenie ich znacznie ułatwia. Kiedy już wiesz, co się dzieje, przeprowadź testy hipotez, aby sprawdzić założenie. Jeśli odrzucisz hipotezę zerową (podstawowe założenie) na rzecz alternatywnej, gratulacje, stworzyłeś „coś prawdziwego”.
Wreszcie, gdy dobrze rozumiesz swoje dane, spróbuj stworzyć kompletny model. Może to być coś ogólnego, jak PGM (np. Ręcznie stworzona sieć bayesowska) lub coś bardziej szczegółowego, jak regresja liniowa lub SVM, lub cokolwiek innego. Ale w jakikolwiek sposób będziesz już wiedział, jak ten model odpowiada Twoim danym i jak możesz zmierzyć jego wydajność. Jako dobre źródło początkowe do nauki podejścia statystycznego polecam kurs „Wprowadzenie do statystyki” Sebastiana Thruna. Chociaż jest dość prosty i nie zawiera zaawansowanych tematów, zawiera opis najważniejszych pojęć i podaje systematyzację
Chociaż nie jestem analitykiem danych, jestem epidemiologiem pracującym w warunkach klinicznych. Twoje pytanie badawcze nie określało okresu (tj. Szans na rozwój PChN w ciągu 1 roku, 10 lat, życia?). Ogólnie rzecz biorąc, przechodziłbym przez kilka kroków, zanim jeszcze pomyślę o modelowaniu (analiza jednowymiarowa, analiza dwuwymiarowa, sprawdzanie współliniowości itp.). Jednak najczęściej używaną metodą prób przewidywania zdarzenia binarnego (przy użyciu zmiennych ciągłych LUB binarnych) jest regresja logistyczna. Jeśli chcesz spojrzeć na CKD jako wartość laboratoryjną (mocz albumina, eGFR) zastosowałbyś regresję liniową (wynik ciągły). Chociaż stosowane metody powinny być oparte na danych i pytaniach, klinicyści są przyzwyczajeni do sprawdzania współczynników szans i współczynników ryzyka, ponieważ są to najczęściej zgłaszane miary powiązań w czasopismach medycznych, takich jak NEJM i JAMA. Jeśli pracujesz nad tym problemem z perspektywy zdrowia ludzkiego (w przeciwieństwie do Business Intelligence) te modele prognozowania klinicznego firmy Steyerberg są doskonałym źródłem informacji.
„Zidentyfikuj najbardziej wpływowe stany prekursorowe (choroby współistniejące) dla schorzeń, takich jak przewlekła choroba nerek”. Nie jestem pewien, czy możliwe jest zidentyfikowanie najbardziej wpływowych schorzeń; Myślę, że to będzie zależało od tego jakiego modelu używasz. Jeszcze wczoraj dopasowałem losowy las i wzmocnione drzewo regresji do tych samych danych, a kolejność i względne znaczenie, jakie każdy model nadał zmiennym, były zupełnie inne.
Kiedy jest wystarczająco dużo danych do uogólnienia?
Czy są jakieś ogólne zasady, na podstawie których można wywnioskować, czego można się nauczyć / uogólnić na podstawie określonego zestawu danych? Załóżmy, że zbiór danych został pobrany z próby osób. Czy te zasady można określić jako funkcje próby lub całej populacji? Rozumiem, że powyższe może być niejasne, więc scenariusz: Użytkownicy biorą udział w wyszukiwaniu zadania, w którym dane są ich zapytaniami, klikniętymi wynikami i zawartością HTML (tylko tekst) tych wyników. Każdy z nich jest oznaczony swoim użytkownikiem i sygnaturą czasową. Użytkownik może wygenerować kilka stron – do prostego zadania polegającego na ustaleniu faktów – lub setki stron – na dłuższy okres zadanie wyszukiwania, jak w przypadku raportu z zajęć. Oprócz uogólniania na temat populacji, biorąc pod uwagę próbkę, interesuje mnie uogólnienie dotyczące ogólnego zachowania osoby podczas wyszukiwania w danym przedziale czasu. Teoria i odniesienia do papieru to plus!
Rozumiem, że losowe pobieranie próbek jest obowiązkowym warunkiem dokonywania jakichkolwiek uogólnień. IMHO, inne parametry, takie jak wielkość próby, po prostu wpływają na poziom prawdopodobieństwa (ufność) uogólnienia. Ponadto, wyjaśniając komentarz @ ffriend, uważam, że musisz obliczyć potrzebną wielkość próby, w oparciu o pożądane wartości przedziału ufności, wielkości efektu, mocy statystycznej i liczby predyktorów (jest to oparte na pracy Cohena – patrz sekcja Referencje poniżej połączyć). W przypadku regresji wielokrotnej możesz skorzystać z następującego kalkulatora:
http://www.danielsoper.com/statcalc3/calc.aspx?id=1.
Więcej informacji na temat doboru, obliczania i interpretowania rozmiarów efektów można znaleźć w następującym ładnym i obszernym artykule, który jest dostępny bezpłatnie:
http://jpepsy.oxfordjournals.org/content/34/9/917.full.
Jeśli używasz R (a nawet, jeśli tego nie robisz), następująca strona internetowa dotycząca przedziałów ufności i R może okazać się interesująca i przydatna:
http://osc.centerforopenscience.org/static/CIs_in_r.html.
Na koniec poniższy kompleksowy przewodnik dotyczący próbkowania ankiet może być pomocny, nawet jeśli nie korzystasz z projektów badań ankietowych. Moim zdaniem zawiera wiele przydatnych informacji na temat metod pobierania próbek, określania wielkości próby (w tym kalkulator) i dużo więcej: http://home.ubalt.edu/ntsbarsh/stat-data/Surveys.htm.
Odpowiedź przez ssdecontrol Istnieją dwie zasady dotyczące możliwości uogólniania:
- Próbka musi być reprezentatywna. Oczekując przynajmniej, że rozkład cech w twojej próbie musi odpowiadać rozkładowi cech w populacji. Kiedy dopasowujesz model ze zmienną odpowiedzi, obejmuje to cechy, których nie obserwujesz, ale które mają wpływ na wszystkie zmienne odpowiedzi w modelu. Ponieważ w wielu przypadkach nie można wiedzieć, czego się nie obserwuje, stosuje się próbkowanie losowe. Idea randomizacji polega na tym, że próba losowa, aż do błędu próbkowania, musi dokładnie odzwierciedlać rozkład wszystkich cech w populacji, obserwowanych i innych. Dlatego randomizacja jest „złotym standardem”, ale jeśli kontrola próbki jest dostępna za pomocą innej techniki lub można obronić argument, że nie ma pominiętych funkcji, to nie zawsze jest to konieczne.
- Twoja próbka musi być na tyle duża, aby wpływ błędu próbkowania na rozkład cech był stosunkowo niewielki. Ma to ponownie na celu zapewnienie reprezentatywności. Jednak decyzja, kogo pobrać próbkę, różni się od decyzji, ile osób ma pobrać próbkę.
Ponieważ wydaje się, że dopasowujesz model, należy wziąć pod uwagę, że niektóre ważne kombinacje cech mogą występować stosunkowo rzadko w populacji. Nie jest to problem związany z możliwością uogólnienia, ale ma to duży wpływ na rozważania dotyczące wielkości próby. Na przykład pracuję teraz nad projektem z (małymi) danymi, które zostały pierwotnie zebrane w celu zrozumienia doświadczeń mniejszości na studiach. W związku z tym niezwykle ważne było zapewnienie wysokiej mocy statystycznej, szczególnie w subpopulacji mniejszościowej. Z tego powodu czarni i Latynosi byli celowo nadpróbkowani. Odnotowano jednak również proporcję, w jakiej zostały one nadpróbkowane. Są one używane do obliczania wag ankiet. Można je wykorzystać do ponownego zważenia próbki, aby odzwierciedlić szacowane proporcje populacji, w przypadku gdy wymagana jest reprezentatywna próbka. Dodatkowa uwaga pojawia się, jeśli model jest hierarchiczny. Kanoniczne zastosowanie modelu hierarchicznego to zachowanie dzieci w szkole. Dzieci są „pogrupowane” według szkoły i mają podobne cechy na poziomie szkolnym. Dlatego wymagana jest reprezentatywna próba szkół, aw każdej szkole wymagana jest reprezentatywna próba dzieci. Prowadzi to do losowania warstwowego. Ten i kilka innych projektów próbkowania są szczegółowo omówione w Wikipedii.
Aby odpowiedzieć na prostsze, ale powiązane pytanie, a mianowicie „Jak dobrze mój model może uogólniać dane, które posiadam?”, Można zastosować metodę uczenia krzywych. To jest wykład wygłoszony przez Andrew Ng na ich temat. Podstawowym pomysłem jest wykreślenie błędu zbioru testowego i błędu zbioru uczącego w funkcji złożoności modelu, którego używasz (może to być nieco skomplikowane). Jeśli model jest wystarczająco wydajny, aby w pełni „zrozumieć” dane, w pewnym momencie złożoność modelu będzie na tyle duża, że wydajność zestawu uczącego będzie bliska ideału. Jednak wariancja złożonego modelu prawdopodobnie spowoduje w pewnym momencie wzrost wydajności zestawu testowego. Myślę, że ta analiza mówi wam dwie główne rzeczy. Pierwsza to górna granica wydajności. Jest mało prawdopodobne, że poradzisz sobie lepiej z danymi, których nie widziałeś, niż z danymi treningowymi.
Inną rzeczą, którą informuje, jest to, czy uzyskanie większej ilości danych może pomóc. Jeśli możesz wykazać, że w pełni rozumiesz swoje dane treningowe, zmniejszając błąd szkolenia do zera, możliwe jest, poprzez włączenie większej ilości danych, dalsze obniżenie błędu testu poprzez uzyskanie pełniejszej próbki, a następnie wyszkolenie na tej podstawie potężnego modelu. .
Rozwiązywanie układu równań z nielicznymi danymi
Próbuję rozwiązać układ równań, który ma 40 zmiennych niezależnych (x1,…, x40) i jedną zmienną zależną (y). Całkowita liczba równań (liczba wierszy) to ~ 300 i chcę rozwiązać zestaw 40 współczynników, który minimalizuje całkowitą sumę kwadratów
błąd między y a przewidywaną wartością. Mój problem polega na tym, że macierz jest bardzo rzadka i nie znam najlepszego sposobu rozwiązania układu równań z nielicznymi danymi. Przykład zbioru danych przedstawiono poniżej:
y x1 x2 x3 x4 x5 x6… x40
87169 14 0 1 0 0 2 … 0
46449 0 0 4 0 1 4 … 12
846449 0 0 0 0 0 3 … 0….
Obecnie używam algorytmu genetycznego, aby rozwiązać ten problem, a wyniki wychodzą z mniej więcej dwukrotną różnicą między obserwowaną a oczekiwaną. Czy ktoś może zasugerować różne metody lub techniki, które są w stanie rozwiązać zestaw równań przy niewielkiej ilości danych.
Jeśli dobrze rozumiem, jest to przypadek wielokrotnej regresji liniowej z rzadkimi danymi (rzadka regresja). Zakładając to, mam nadzieję, że poniższe zasoby okażą się przydatne.
1) Slajdy z wykładu NCSU na temat regresji rzadkiej z omówieniem algorytmów, uwag, wzorów, grafik i odniesień do literatury:
http://www.stat.ncsu.edu/people/zhou/courses/st810/notes/lect23sparse.pdf
2) Ekosystem R oferuje wiele pakietów przydatnych do rzadkiej analizy regresji, w tym:
* Matrix (http://cran.r-project.org/web/packages/Matrix)
* SparseM (http://cran.r-project.org/web/packages/SparseM)
* MatrixModels (http://cran.r-project.org/web/packages/MatrixModels)
* glmnet (http://cran.r-project.org/web/packages/glmnet)
* flara (http://cran.r-project.org/web/packages/flare)
3) Wpis na blogu z przykładem rozwiązania rzadkiej regresji opartego na SparseM:
http://aleph-nought.blogspot.com/2012/03/multiple-linear-regression-with-sparse.html
4) Wpis na blogu o używaniu rzadkich macierzy w R, który zawiera podkład na temat używania glmnet:
5) Więcej przykładów i dyskusję na ten temat można znaleźć na StackOverflow:
http://stackoverflow.com/questions/3169371/large-scale-regression-in-r-with-a-sparsefeature-matrix
UPDATE (na podstawie Twojego komentarza):
Jeśli próbujesz rozwiązać problem LP z ograniczeniami, przydatny może być ten artykuł teoretyczny: http://web.stanford.edu/group/SOL/papers/gmsw84.pdf.
Sprawdź również pakiet R limSolve: http: //cran.r- project.org/web/packages/limSolve. I ogólnie sprawdzaj pakiety w widoku zadań CRAN „Optimization and Mathematical Programming”: http://cran.r-project.org/web/views/Optimization.html.
Sposób postawienia pytania sugeruje, że jest to proste, zwykłe pytanie regresji metodą najmniejszych kwadratów: minimalizowanie sumy kwadratów reszt między zmienną zależną a liniową kombinacją predyktorów. Teraz, gdy macierz projektu może zawierać wiele zer, system jako taki nie jest zbyt duży: 300 obserwacji na 40 predyktorach to nie więcej niż średniej wielkości. Możesz uruchomić taką regresję przy użyciu R bez specjalnego wysiłku w przypadku rzadkich danych. Po prostu użyj polecenia lm () (dla „modelu liniowego”). Użyj? Lm, aby wyświetlić stronę pomocy. Zauważ, że lm domyślnie po cichu doda stałą kolumnę jedynek do macierzy projektu (punkt przecięcia z osią) – dołącz -1 po prawej stronie formuły, aby to powstrzymać. Ogólnie zakładając, że wszystkie twoje dane (i nic więcej) znajdują się w data.frame o nazwie foo, możesz to zrobić:
model <- lm (y ~.-1, dane = foo)
Następnie możesz spojrzeć na szacunki parametrów itp. W ten sposób:
summary(model)
residuals(model)
Jeśli twój system jest znacznie większy, powiedzmy rzędu 10 000 obserwacji i setek predyktorów, spojrzenie na wyspecjalizowane, rzadkie solwery, zgodnie z odpowiedzią Aleksandra, może zacząć mieć sens. Wreszcie, w swoim komentarzu do odpowiedzi Aleksandra, wspominasz o ograniczeniach
równanie. Jeśli rzeczywiście jest to twój kluczowy problem, są sposoby na obliczenie najmniejszych kwadratów z ograniczeniami w R. Osobiście lubię pcls () w pakiecie mgcv. Być może chcesz zmodyfikować swoje pytanie, aby uwzględnić rodzaj ograniczeń (ograniczenia pola, ograniczenia nieujemności, ograniczenia integralności, ograniczenia liniowe,…), z którymi masz do czynienia?
Klasyfikacja wyjątków Java
Mamy algorytm klasyfikacyjny do kategoryzowania wyjątków Java w środowisku produkcyjnym. Algorytm ten jest oparty na hierarchicznych regułach definiowanych przez człowieka, więc kiedy pojawia się zbiór tekstu tworzącego wyjątek, określa, jakiego rodzaju jest wyjątek (rozwój, dostępność, konfiguracja itp.) I komponent odpowiedzialny (najbardziej wewnętrzny komponent odpowiedzialny za wyjątek). W Javie wyjątek może mieć kilka wyjątków powodujących, a całość musi zostać przeanalizowana.
Na przykład biorąc pod uwagę następujący przykładowy wyjątek:
com.myapp.CustomException: Błąd podczas drukowania…
… (stos)
Przyczyna: com.foo.webservice.RemoteException: brak możliwości komunikacji…
… (stos)
Spowodowany przez: com.acme.PrintException: PrintServer002: Timeout….
… (stos)
Po pierwsze, nasz algorytm dzieli cały stos na trzy pojedyncze wyjątki. Następnie zaczyna analizować te wyjątki, zaczynając od najbardziej wewnętrznego. W tym przypadku określa, że ten wyjątek (drugi spowodowany przez) jest typu Dostępność, a odpowiedzialnym składnikiem jest „serwer druku”. Dzieje się tak, ponieważ istnieje reguła, która pasuje, zawierająca słowo Timeout skojarzone z typem dostępności. Istnieje również reguła, która pasuje do com.acme.PrintException i określa, że odpowiedzialnym składnikiem jest serwer druku. Ponieważ wszystkie potrzebne informacje są określane przy użyciu tylko najbardziej wewnętrznego wyjątku, górne wyjątki są ignorowane, ale nie zawsze tak jest. Jak widać, ten rodzaj przybliżenia jest bardzo złożony (i chaotyczny), ponieważ człowiek musi tworzyć nowe reguły, gdy pojawiają się nowe wyjątki. Poza tym nowe zasady muszą być zgodne z obecnymi, ponieważ nowa zasada dotycząca klasyfikacji nowego wyjątku nie może zmieniać klasyfikacji żadnego z już sklasyfikowanych wyjątków. Myślimy o wykorzystaniu uczenia maszynowego do automatyzacji tego procesu. Oczywiście nie proszę tutaj o rozwiązanie, ponieważ znam złożoność, ale naprawdę byłbym wdzięczny za kilka rad, aby osiągnąć nasz cel.
Przede wszystkim trochę podstaw klasyfikacji (i ogólnie wszelkich nadzorowanych zadań ML), aby upewnić się, że mamy na myśli ten sam zestaw pojęć. Każdy nadzorowany algorytm ML składa się z co najmniej 2 elementów:
- Zbiór danych do trenowania i testowania.
- Algorytm (y) do obsługi tych danych.
Zbiór danych uczących składa się ze zbioru par (x, y), gdzie x jest wektorem cech, a y jest zmienną przewidywaną. Zmienna przewidywana jest właśnie tym, co chcesz wiedzieć, czyli w twoim przypadku jest to typ wyjątku. Funkcje są bardziej skomplikowane. Nie możesz po prostu wrzucić surowego tekstu do algorytmu, musisz najpierw wyodrębnić jego znaczące części i uporządkować je jako wektory cech. Wspomniałeś już o kilku przydatnych funkcjach – nazwie klasy wyjątku (np. Com.acme.PrintException) i zawartych słowach („Limit czasu”). Wszystko, czego potrzebujesz, to przetłumaczenie wyjątków wierszy (i typów wyjątków skategoryzowanych przez ludzi) na odpowiedni zbiór danych, np .:
ex_class contains_timeout … | ex_type
————————————————– ———
[com.acme.PrintException, 1, …] | Dostępność
[java.lang.Exception, 0, …] | Sieć
…
Ta reprezentacja jest już znacznie lepsza dla algorytmów ML. Ale który wziąć? Biorąc pod uwagę charakter zadania i obecne podejście, naturalnym wyborem jest użycie drzew decyzyjnych. Ta klasa algorytmów obliczy optymalne kryteria decyzji dla wszystkich typów wyjątków i wydrukuje drzewo wynikowe. Jest to szczególnie przydatne, ponieważ będziesz mieć możliwość ręcznego sprawdzenia, jak podejmowana jest decyzja i zobacz, w jakim stopniu odpowiada ona Twoim ręcznie stworzonym regułom. Istnieje jednak możliwość, że niektóre wyjątki z dokładnie tymi samymi funkcjami będą należeć do różnych typów wyjątków. W takim przypadku podejście probabilistyczne może działać dobrze. Pomimo swojej nazwy klasyfikator Naive Bayes działa w większości przypadków całkiem dobrze. Jest jednak jeden problem z NB i reprezentacją naszego zbioru danych: zbiór danych zawiera dane kategoryczne zmienne, a Naive Bayes może pracować tylko z atrybutami liczbowymi *. Standardowym sposobem rozwiązania tego problemu jest użycie zmiennych fikcyjnych. Krótko mówiąc, zmienne fikcyjne to zmienne binarne, które po prostu wskazują, czy dana kategoria występuje, czy nie. Na przykład pojedyncza zmienna ex_class o wartościach {com.acme.PrintException, java.lang.Exception, …} itd. Może zostać podzielona na kilka zmiennych
![]()
Ostatni algorytm do wypróbowania to Support Vector Machines (SVM). Nie zapewnia pomocnej wizualizacji ani nie jest probabilistyczna, ale często daje lepsze wyniki.
– w rzeczywistości ani twierdzenie Bayesa, ani sam Naive Bayes nie mówią nic o typach zmiennych, ale większość pakietów oprogramowania, które przychodzą na myśl, opiera się na funkcjach numerycznych.
Czy Random Forest jest za dużo?
Czytałem o Random Forests, ale tak naprawdę nie mogę znaleźć ostatecznej odpowiedzi na temat problemu nadmiernego wyposażenia. Według oryginalnego artykułu Breimana, nie powinny one nadmiernie dopasowywać się przy zwiększaniu liczby drzew w lesie, ale wydaje się, że nie ma co do tego zgody. To wprowadza mnie w zakłopotanie w tej kwestii. Może ktoś bardziej ekspert ode mnie może udzielić mi bardziej konkretnej odpowiedzi lub wskazać mi właściwy kierunek, aby lepiej zrozumieć problem.
Możesz chcieć sprawdzić cross-validated – witrynę internetową stachexchange dla wielu rzeczy, w tym uczenia maszynowego. W szczególności na to pytanie (z dokładnie tym samym tytułem) udzielono już wielu odpowiedzi. Sprawdź te linki: http://stats.stackexchange.com/search?
q = losowy + las + przebranie
Mogę jednak udzielić Ci krótkiej odpowiedzi: tak, to przesadza i czasami musisz kontrolować złożoność drzew w swoim lesie, a nawet przycinać, gdy rosną zbyt mocno – ale to zależy od biblioteki, w której używasz budowanie lasu. Na przykład. w random Forest w R możesz tylko kontrolować złożoność
Biblioteki uczenia maszynowego dla Rubiego
Czy istnieją biblioteki uczenia maszynowego dla Rubiego, które są stosunkowo kompletne (w tym szeroki wybór algorytmów do uczenia nadzorowanego i nienadzorowanego), solidnie przetestowane i dobrze udokumentowane? Uwielbiam scikit-learn w Pythonie za niesamowitą dokumentację, ale klient wolałby pisać kod w języku Ruby, ponieważ to jest to, co jest mu znane. Idealnie szukam biblioteki lub zestawu bibliotek, które, podobnie jak scikit i numpy, mogą zaimplementować szeroką gamę struktur danych, takich jak rzadkie macierze, a także uczniów. Niektóre przykłady rzeczy, które będziemy musieli zrobić, to klasyfikacja binarna za pomocą maszyn SVM i implementacja modeli zbioru słów, które mamy nadzieję połączyć z dowolnymi danymi liczbowymi, zgodnie z tym, co opisano w tym poście Stackoverflow.
Pójdę dalej i na razie opublikuję odpowiedź; jeśli ktoś ma coś lepszego, przyjmuję jego. W tym momencie wydaje się, że najpotężniejszą opcją jest dostęp do WEKA za pomocą jRuby. Spędziliśmy wczoraj przeszukiwanie sieci, a ta kombinacja była nawet używana podczas przemówienia na RailsConf 2012, więc zgaduję, że gdyby istniał porównywalny czysty pakiet rubinowy, oni użyliby go. Zauważ, że jeśli wiesz dokładnie, czego potrzebujesz, istnieje wiele indywidualnych bibliotek, które albo opakowują samodzielne pakiety, takie jak libsvm, albo ponownie implementują niektóre indywidualne algorytmy, takie jak Naive Bayes w czystym Rubim, i oszczędzą ci używania jRuby. Ale w przypadku biblioteki ogólnego przeznaczenia WEKA i jRuby wydają się w tej chwili najlepszym wyborem.
Krótki przewodnik po treningu wysoce niezrównoważonych zestawów danych
Mam problem klasyfikacyjny z około 1000 pozytywnymi i 10000 negatywnymi próbkami w zbiorze uczącym. Więc ten zestaw danych jest dość niezrównoważony. Zwykły las losowy próbuje po prostu oznaczyć wszystkie próbki testowe jako klasę większościową. Oto kilka dobrych odpowiedzi na temat próbkowania podrzędnego i lasu losowego ważonego: Jakie są implikacje dla trenowania Zespołu Drzewa z wysoce stronniczymi zestawami danych? Które metody klasyfikacji poza RF mogą najlepiej rozwiązać problem?
* Max Kuhn dobrze to opisuje w rozdziale 16 Applied Predictive Modeling.
* Jak wspomniano w powiązanym wątku, niezrównoważone dane są zasadniczo problemem szkoleniowym wrażliwym na koszty. W związku z tym każde podejście wrażliwe na koszty ma zastosowanie do niezrównoważonych danych.
* Istnieje duża liczba takich podejść. Nie wszystkie zaimplementowane w R: C50, ważone SVM są opcjami. Jous-boost. Myślę, że Rusboost jest dostępny tylko jako kod Matlab.
* Nie używam Weka, ale uważam, że ma dużą liczbę klasyfikatorów wrażliwych na koszty.
* Obsługa niezrównoważonych zbiorów danych: przegląd: Sotiris Kotsiantis, Dimitris Kanellopoulos, Panayiotis Pintelas ”
* W przypadku problemu nierównowagi klas: Xinjian Guo, Yilong Yin, Cailing Dong, Gongping Yang, Guangtong Zhou
Podpróbkowanie klasy większości jest zwykle dobrym rozwiązaniem w takich sytuacjach. Jeśli uważasz, że masz za mało instancji klasy pozytywnej, możesz wykonać nadpróbkowanie, na przykład próbkowanie 5n instancji, zastępując je ze zbioru danych o rozmiarze n.
Ostrzeżenia:
* Niektóre metody mogą być wrażliwe na zmiany w rozkładzie klas, np. dla Naive Bayes – wpływa na wcześniejsze prawdopodobieństwa.
* Oversampling może prowadzić do overfittingu
W tym przypadku dobrym wyborem jest również wzmocnienie gradientowe. Możesz na przykład użyć klasyfikatora zwiększającego gradient w Sci-Kit Learn. Zwiększanie gradientu to oparta na zasadach metoda radzenia sobie z nierównowagą klas poprzez konstruowanie kolejnych zestawów treningowych na podstawie nieprawidłowo sklasyfikowanych przykładów.
Szukasz mocnego tematu doktorskiego z zakresu analizy predykcyjnej w kontekście Big Data
W tym roku zamierzam rozpocząć doktorat z informatyki, a do tego potrzebuję tematu badawczego. Interesuje mnie Predictive Analytics w kontekście Big Data. Interesuje mnie obszar edukacji (kursy MOOC, kursy online…). W tej dziedzinie, jakie niezbadane obszary mogą pomóc mi wybrać mocny temat?
Jako stypendysta CS Ph.D. broniąc mojej pracy doktorskiej w tym roku w temacie związanym z Big Data (zacząłem w 2012 roku), najlepszy materiał, jaki mogę Ci dać, znajduje się w linku: http://www.rpajournal.com/dev/wp-content/uploads /2014/10/A3.pdf
To jest artykuł napisany przez dwóch doktorów z MIT, którzy rozmawiali o Big Data i MOOC. Prawdopodobnie uznasz to za dobry punkt wyjścia. A tak przy okazji, jeśli naprawdę chcesz wymyślić ważny temat (który komisja i twój doradca pozwolą ci zaproponować, zbadać i obronić), musisz przeczytać WIELE i WIELE artykułów. Większość doktorów uczniowie popełniają fatalny błąd, myśląc, że jakiś „pomysł”, który mają, jest nowy, podczas gdy tak nie jest i został już wykonany. Będziesz musiał zrobić coś naprawdę oryginalnego, aby zdobyć doktorat. Zamiast skupiać się na formułowaniu pomysłu w tej chwili, powinieneś zrobić dobry przegląd literatury, a pomysły „zasugerują się”. Powodzenia! To ekscytujący czas dla Ciebie.
Podobieństwo cosinusowe dla rekomendacji ocen? Po co go używać?
Powiedzmy, że mam bazę użytkowników, którzy oceniają różne produkty w skali 1-5. Nasz silnik rekomendacji rekomenduje produkty użytkownikom na podstawie preferencji innych użytkowników, którzy są bardzo podobni. Moim pierwszym podejściem do znalezienia podobnych użytkowników było użycie podobieństwa kosinusowego i traktowanie ocen użytkowników jako komponentów wektorowych. Główny problem z tym podejściem polega na tym, że mierzy ono tylko kąty wektora i nie bierze pod uwagę skali oceny ani wielkości. Moje pytanie brzmi:
Czy są jakieś wady stosowania różnicy procentowej między składowymi wektorów dwóch wektorów jako miary podobieństwa? Jakie wady, jeśli w ogóle, napotkałbym, gdybym użył tej metody zamiast podobieństwa cosinusowego lub odległości euklidesowej?
Na przykład, dlaczego nie zrobić tego po prostu:
n = 5 gwiazdek
a = (1,4,4)
b = (2, 3, 4)
podobieństwo (a, b) = 1 – ((| 1-2 | / 5) + (| 4-3 | / 5) + (| 4-4 | / 5)) / 3 = .86667
Zamiast podobieństwa cosinusowego:
a = (1,4,4)
b = (2, 3, 4)
CosSimilarity (a, b) =
(1 * 2) + (4 * 3) + (4 * 4) / sqrt ((1 ^ 2) + (4 ^ 2) + (4 ^ 2)) * sqrt ((2 ^ 2) + (3 ^ 2) + (4 ^ 2)) = 0,9697
Odchylenie i skalę ocen można łatwo uwzględnić poprzez standaryzację. Istotą wykorzystania metryk podobieństwa euklidesowego we współ-osadzaniu w przestrzeni wektorowej jest to, że ogranicza to problem rekomendacji do znalezienia najbliższych sąsiadów, co można wykonać efektywnie zarówno dokładnie, jak iw przybliżeniu. To, czego nie chcesz robić w rzeczywistych ustawieniach, to porównywać każdą parę element / użytkownik i sortować je według kosztownych danych. To po prostu się nie skaluje. Jedną sztuczką jest użycie przybliżenia, aby ubić stado do rozsądnego rozmiaru wstępnych zaleceń, a następnie przeprowadzić na tym kosztowny ranking. edycja: Microsoft Research przedstawia artykuł, który omawia ten temat w RecSys w tej chwili: Przyspieszenie systemu rekomendacji Xbox przy użyciu transformacji euklidesowej dla przestrzeni produktów wewnętrznych
Odpowiedź buruzaemona Jeśli chodzi o oceny, myślę, że do pomiaru podobieństwa należałoby użyć korelacji rang Spearmana. Podobieństwo cosinusowe jest często używane podczas porównywania dokumentów i być może nie będzie dobrze pasować do zmiennych rang. Odległość euklidesowa jest odpowiednia dla niższych wymiarów, ale porównanie zmiennych rang zwykle wymaga Spearmana. Oto pytanie dotyczące CrossValidated dotyczące Spearman (vs Pearson), które może rzucić więcej światła na Ciebie.
P: Sztuczka haszująca – co się właściwie dzieje
Kiedy algorytmy ML, np. Vowpal Wabbit lub niektóre maszyny do faktoryzacji wygrywające konkursy współczynnika klikalności (Kaggle), wspominają, że funkcje są „zaszyfrowane”, co to właściwie oznacza dla modelu? Powiedzmy, że istnieje zmienna reprezentująca identyfikator dodatku internetowego, która przyjmuje wartości takie jak „236BG231”. Wtedy rozumiem, że ta funkcja jest haszowana do losowej liczby całkowitej. Ale moje pytanie brzmi: czy liczba całkowita jest teraz używana w modelu jako liczba całkowita (numeryczna), LUB czy wartość zaszyfrowana jest nadal traktowana jak zmienna kategorialna i zakodowana na gorąco? Zatem sztuczka polegająca na haszowaniu polega na tym, aby jakoś zaoszczędzić miejsce przy dużych danych?
Drugi punkt to wartość podczas mieszania funkcji. Haszowanie i jedno gorące kodowanie w celu uzyskania rzadkich danych oszczędza miejsce. W zależności od hash algo możesz mieć różne stopnie kolizji, co działa jako rodzaj redukcji wymiarowości. Ponadto w konkretnym przypadku mieszania funkcji Kaggle i jednego gorącego kodowania pomaga w rozszerzaniu / inżynierii funkcji poprzez pobieranie wszystkich możliwych krotek (zwykle tylko drugiego rzędu, ale czasami trzeciego) funkcji, które są następnie mieszane z kolizjami, które wyraźnie tworzą interakcje, które często są predykcyjne podczas gdy indywidualne cechy nie. W większości przypadków ta technika w połączeniu z wyborem cech i regulacją elastycznej siatki w LR działa bardzo podobnie do jednej warstwy ukrytej NN, więc sprawdza się całkiem dobrze w zawodach
Od czego zacząć w sieciach neuronowych
Przede wszystkim wiem, że to pytanie może nie pasować do tej witryny, ale byłbym wdzięczny, gdybyś podał mi kilka wskazówek. Jestem 16-letnim programistą, miałem doświadczenie z wieloma różnymi językami programowania, jakiś czas temu zacząłem kurs w Coursera, zatytułowany wprowadzenie do uczenia maszynowego i od tego momentu bardzo zmotywowałem się do nauki AI, zacząłem czytając o sieciach neuronowych i zrobiłem działający perceptron używając Javy i było naprawdę fajnie, ale kiedy zacząłem robić coś bardziej wymagającego (budowanie oprogramowania do rozpoznawania cyfr), okazało się, że muszę się dużo nauczyć matematyki, kocham matematykę, ale tutejsze szkoły niewiele nas uczą, myślisz, że teraz znam kogoś, kto jest nauczycielem matematyki ,uczenie się matematyki (w szczególności rachunku różniczkowego) jest konieczne do nauki sztucznej inteligencji, czy powinienem poczekać, aż nauczę się tych rzeczy w szkole? Jakie inne rzeczy byłyby pomocne na mojej ścieżce uczenia się AI i uczenia maszynowego? czy inne techniki (takie jak SVM) również wymagają mocnej matematyki? Przepraszam, jeśli moje pytanie jest długie, byłbym wdzięczny, gdybyś mógł mi je przekazać doświadczenie w nauce sztucznej inteligencji.
Nie, powinieneś sam nauczyć się matematyki. Będziesz musiał „tylko” nauczyć się rachunku różniczkowego, statystyki i algebry liniowej (podobnie jak reszty uczenia maszynowego). Teoria sieci neuronowych jest w tej chwili dość prymitywna – to bardziej sztuka niż nauka – więc niż myślisz, że możesz to zrozumieć, jeśli spróbujesz. I tak samo jest wiele sztuczek, których trzeba się nauczyć. Istnieje wiele skomplikowanych rozszerzeń, ale możesz się nimi martwić, gdy zajdziesz tak daleko. Kiedy już zrozumiesz zajęcia Coursera z ML i sieci neuronowych (Hinton’s), proponuję trochę poćwiczyć. To wprowadzenie może Ci się spodobać.
Powiedziałbym… to naprawdę zależy. Może być konieczne: używaj algorytmów uczenia maszynowego: będzie to przydatne w przypadku określonych aplikacji, które możesz mieć. W tej sytuacji potrzebujesz umiejętności programowania i zamiłowania do testowania (ćwiczenie doda siły). Tutaj matematyka nie jest tak bardzo wymagana, powiedziałbym, że można modyfikować istniejące algorytmy. Twoja konkretna aplikacja może nie odpowiadać zwykłym algorytmom, więc może być konieczne dostosowanie ich w celu uzyskania maksymalnej wydajności. Tutaj w grę wchodzi matematyka. zrozumieć teorię algorytmów. Tutaj matematyka jest niezbędna i pomoże ci poszerzyć wiedzę w dziedzinie uczenia maszynowego, opracować własne algorytmy, mówić tym samym językiem co twoi rówieśnicy… Teoria NN może być prymitywna, jak mówi @Emre, ale na przykład nie jest to przypadek SVM (teoria stojąca za SVM wymaga np. zrozumienia odtwarzających się przestrzeni jądra Hilberta). W połowie semestru na pewno będziesz potrzebować mocnej matematyki. Ale nie musisz czekać, aż przyjdą do ciebie, możesz zacząć od razu od algebry liniowej, która jest piękna i przydatna do wszystkiego. A jeśli napotkasz (być może tymczasowe) jakiekolwiek trudności z matematyką, ćwicz dalej w sposób, w jaki już to zrobiłeś (wiele osób może mówić o perceptronie, ale nie jest w stanie stworzyć perceptronu w Javie), jest to bardzo cenne.